|
Tóm
tắt
Những ghi chú
có tính cách tổng quan trong bài này có tham
vọng phác họa một khung cảnh chung cho những
nghiên cứu và phát triển trong Công Nghệ Thông
Tin (CNTT) trên khía cạnh xử lý phân tán, ở tầm
mức của mạng toàn cầu Internet.
Để nắm bắt
khuynh hướng tiến triển của CNTT trong chiều
hướng ấy, những điều cơ bản cần thiết tìm hiểu
là : 1) Chuẩn CORBA, cho phép các sự vật tin học
phân tán cộng tác được với nhau ; 2) Chuẩn XML,
xác định ngôn ngữ giao diện cho mạng Internet,
tổng quát hơn ngôn ngữ HTML ; 3) Ngôn ngữ Java,
cho phép chỉ viết chương trình một lần để nó
hoạt động được ở bất cứ nơi nào ; và 4) Công
nghệ tác tử, công nghệ để thực hiện trong tương
lai những ứng dụng di động và có trí tuệ. Bốn
công nghệ nói trên đang trên đà hội tụ để thể
hiện một tổng hợp mới giữa tin học và viễn
thông, và hình thành một mô thức mới trong hoạt
động phát triển mạng thông tin cũng như dịch vụ
CNTT trong thời đại Internet.
Trong tương
lai không xa các điều kiện sẽ hội đủ để cho phép
có những ứng dụng tiên tiến của CNTT, mà đặc
tính là dễ dùng, phân tán và di động trong phạm
vi toàn cầu. Có thể tiên đoán là chúng sẽ đẩy
mạnh những thay đổi trong sinh hoạt kinh tế xã
hội của con người nói chung, và lao động trí óc
nói riêng, trên đà khởi động bởi Internet. ' Tác
tử di động' là một trong những công cụ để thực
hiện những ứng dụng nói trên, bằng cách kết hợp
những thành quả thừa hưởng từ các nghiên cứu và
phát triển về xử lý phân tán và về trí tuệ nhân
tạo trong nhiều năm qua.
1. Dẫn nhập
Hiện nay cái
nhìn về kiến trúc mạng thông tin của cộng đồng
những người công tác trong ngành công nghệ thông
tin (CNTT) trên thế giới chưa được rõ ràng lắm.
Điều đó cũng dễ hiểu, vì nhiều yếu tố đang ảnh
hưởng mạnh đến các quan niệm về kiến trúc mạng
nhưng lại chưa ổn định : sự bùng nổ của Internet
đưa đến vai trò nổi trội của mạng thông tin số
liệu lên trên mạng điện thoại về mặt kinh tế ;
đồng thời nhiều tiến bộ vượt bực về kỹ thuật
truyền tin như sợi quang dẫn, kỹ thuật vô
tuyến... làm cho các dịch vụ đa mêđia 2hiện
chỉ được thỏa mãn cục bộ với một máy tính cá
nhân, sẽ được thực hiện phổ biến trên mạng tầm
rộng. Trong khung cảnh đó các tập đoàn kinh tế -
kỹ thuật vừa phải thương lượng với nhau trong
các tổ chức ngành nghề quốc tế như OMG (Object
Management Group), W3C (World Wide Web
Consortium)... để xác định các chuẩn không thể
thiếu trong việc phát triển CNTT ; vừa đấu tranh
với nhau để chiếm ảnh hưởng lớn cho cái sở
trường của mình ; vừa lại có thể liên kết với
nhau để mở rộng thị trường theo những xu hướng
của thời đại. Theo các tầng lớp của CNTT từ dưới
lên trên có thể kể : các tập đoàn sản xuất và
khai thác mạng truyền tin như Alcatel, AT&T,
Cisco, Lucent, Nortel, France Telecom... các tập
đoàn bán dịch vụ Internet như AOL... các tập
đoàn làm tin học cổ điển hơn như Microsoft, Sun,
IBM... Đáng chú ý là các tập đoàn này có mặt
trong các tổ chức ngành nghề khác nhau, và nhiều
khi bảo vệ các giải pháp khác nhau, vì bản thân
trong nội bộ họ cũng không thống nhất, hay không
cần thống nhất ; một hãng lớn rất có thể có lợi
ích để nuôi dưỡng nhiều nhóm làm việc trên (và
bảo vệ) các chuẩn mâu thuẫn với nhau, trong tình
trạng các chuẩn này còn chưa chín mùi và cần
nghiên cứu và phát triển thêm. Điều đó khiến cho
việc dự đoán tương lai lại càng thêm khó khăn.
CORBA (Common
Object Request Broker Architecture) là một chuẩn
hết sức quan trọng ra đời trong khung cảnh này,
nó nhằm cho phép thực hiện kiến trúc "khách-hàng
- phục-vụ" theo phương pháp tiếp cận hướng sự
vật, trên những hệ thống máy khác nhau và phân
tán, để cho phép nhiều nhóm sản xuất phần mềm
khác nhau cùng cộng tác. Chuẩn CORBA khi đầu chỉ
được quan niệm với các phần mềm 'cố định' và
hoạt động phân tán trong một mạng cục bộ. Chuẩn
này vừa ra đời thì cũng cùng lúc đó xuất hiện
ngôn ngữ Java và công nghệ tác tử, cho phép mỗi
khi cần dùng thì bản thân trạm phục vụ thông qua
mạng nạp xuống vào máy khách những tác tử 'khách
hàng', do đó việc chuẩn hoá giao diện "khách
hàng-phục vụ" ở mức độ ứng dụng trở nên đơn giản
hơn. Thêm nữa, với sự bùng nổ Internet thì mở
rộng CORBA để xử lý phân tán ở mạng tầm rộng qua
Internet trở thành quan trọng, và khi đó phải
kết hợp CORBA với ngôn ngữ giao diện XML của
Internet, XML đang được triển khai để mở rộng
HTML mà chúng ta quen thuộc, vì cái áo HTML đã
quá chật.
Tìm hiểu chuẩn
CORBA, chuẩn XML, ngôn ngữ Java và công nghệ tác
tử vì thế trở nên thiết yếu để nắm bắt những
khuynh hướng tiến triển của CNTT trong nghĩa một
tổng hợp mới giữa tin học và viễn thông. Chẳng
hạn, khuynh hướng làm các "trạm vấn tin mỏng"
(thin terminal) ở giữa khả năng của một trạm vấn
tin "quá dốt" (dumb) như thời xưa, và một loại
trạm vấn tin "quá nặng nề" cần chứa sẵn quá
nhiều chương trình như hiện nay, chính vì khả
năng truy nạp nói trên. Nhưng, như chúng ta sẽ
thấy, công nghệ tác tử sẽ không chỉ dừng ở đó,
nó còn cho phép nghĩ tới việc thực hiện dễ dàng
các thuật toán phân tán và di động trên mạng
thông tin tầm rộng để tận dụng khả năng gần như
vô hạn của sức tính toán và xử lý thông tin nằm
trong mạng rộng, có thể thích hợp cho nhiều lớp
bài toán hữu ích, tuy rằng không phải là cho mọi
bài toán.
Bài này có 5
phần chính, sau đoạn 2 điểm lại các ngôn ngữ lập
trình và các mô hình quy chiếu thì có 4 đoạn lần
lượt đề cập đến CORBA, XML, Java và tác tử. Các
chuẩn và công nghệ này có liên hệ chặt chẽ với
nhau, tuy rằng việc tích hợp chúng thành một thể
thống nhất chưa hoàn chỉnh và còn cần nhiều
nghiên cứu và phát triển, người ta có thể nhận
thấy rõ rệt chúng đang trên đà hội tụ. Điểm bài
này muốn làm sáng tỏ là vị trí trung tâm của
ngôn ngữ Java và vị trí mũi nhọn của các nghiên
cứu về tác tử di động, dựa trên hai chuẩn thiết
yếu là CORBA và XML.
Những ghi chú
trong bài này chỉ có tham vọng phác họa một
khung cảnh chung cho những nghiên cứu và phát
triển của CNTT, giới hạn trong khía cạnh xử lý
phân tán trên mạng rộng. Với đối tượng là các
người thực sự đi vào nghiên cứu thì hy vọng bài
này giúp đỡ cho việc đọc những tài liệu kỹ thuật
về những vấn đề này được dễ dàng hơn, nhưng nó
không thể thay thế cho việc tìm hiểu sâu những
tài liệu kỹ thuật đó.
Sau cùng, bài
này có một tham vọng bên lề là đề nghị một số
thuật ngữ mới mà người viết chưa được biết là có
sẵn, và sử dụng chúng trong khung cảnh một bài
viết để thử nghiệm.
2. Điểm lại các ngôn
ngữ và mô hình quy chiếu
2.1. Ngôn ngữ
lập trình
Kể từ khi phát
minh ra máy tính điện tử, so với sự tiến triển
của thiết bị thì sự tiến triển của phần mềm luôn
luôn là chậm chạp, đầy những hăm hở sôi nổi
tưởng rằng làm gì cũng dễ, và tiếp theo là nguội
lạnh nản lòng. Các hợp ngữ (assemblers) ra đời
khá nhanh từ những năm 50, và khi ấy đôi khi
cũng đã được gọi là ngôn ngữ lập trình tự
động ! Rồi đến những năm 60, COBOL và
FORTRAN... xuất hiện như những tiến bộ vượt
bực... Nhưng cuối cùng người ta nhận thấy ngôn
ngữ lập trình không đủ để tự nó cho phép làm nên
những sản phẩm hệ mềm có chất lượng. Người ta
thấy thiếu ở phía hạ nguồn những phép tắc, những
kỷ luật lập trình ; và thiếu ở phía thượng nguồn
những phương pháp mô hình hoá một cách dễ hiểu
và trong sáng các vấn đề cần giải quyết ; cũng
như là, đi song song với tiến trình phát triển
một sản phẩm hệ mềm lớn, còn cần có những quy
trình và công cụ để tổ chức, quản lý đề án một
cách chặt chẽ. Một phần nào của những ý niệm
trên đã được tích hợp vào trong các ngôn ngữ lập
trình hiện đại và các mô hình quy chiếu được
chuẩn hoá, nhưng dĩ nhiên không thể là tất cả.
Khái niệm
lập trình có cấu trúc (structured
programming) là một thành quả của những năm
70, cho tới nay vẫn còn giữ nguyên giá trị.
Khái niệm này phần nào được lồng trong cơ
cấu của tất cả những ngôn ngữ lập trình kể
từ ALGOL, Pascal, C ...
Mặt khác
người ta ý thức được rằng cần bảo vệ các dữ
liệu bằng cách 'bao bọc' chung quanh chúng
những thao tác đặc thù theo từng kiểu dữ
liệu (những thao tác này hiện nay gọi là
những phương pháp (methods) trong
ngôn ngữ hướng sự vật). Dữ liệu và phương
pháp được gộp lại trong một thể thống nhất
ngày nay gọi là sự vật (object).
Người đã đưa ra khái niệm đó từ cuối những
năm 60, và gọi là kiểu dữ liệu trừu tượng
(abstract data type) là bà Barbara Liskov,
hiện nay là giáo sư đại học MIT. Nhưng khái
niệm này chỉ trở thành quen thuộc từ những
năm 80 - 90 với các ngôn ngữ SIMULA, SMALL
TALK, và nhất là C++ ...
Hướng tiến
bộ thứ ba phát triển từ cuối những năm 80 là
việc đưa vào các ngôn ngữ lập trình cấp cao
việc mô tả và điều khiển các tiến trình song
hành có liên hệ chặt chẽ với nhau, chứ không
chỉ để cho các hệ điều hành quản lý một cách
tự động (việc này tốt cho những tiến trình
không hoặc rất ít liên hệ) ; hoặc để cho mỗi
hệ mềm 'thời gian thực' lớn phải tự viết lấy
việc điều khiển đó, như đã phải làm trong
các hệ thời gian thực của những năm 70-80.
Ngôn ngữ
lập trình tổng hợp được tốt nhất những khái
niệm trên có lẽ là ngôn ngữ ADA, do bộ quốc
phòng Mỹ đặt yêu cầu và lựa chọn. Nhưng ADA
không được sử dụng nhiều ngoài môi trường
'thời gian thực', có lẽ vì những lý do lịch
sử ; và ADA cũng chưa có các công cụ thuận
tiện cho việc cộng tác của các máy tính điện
tử với nhau trên mạng. Vấn đề này trở nên
chủ yếu trong thời đại ngày nay khi viễn
thông và tin học đang hoà nhập vào nhau.
Ở đây không
đề cập tới nhiều loại ngôn ngữ lập trình
chuyên dụng và khác hẳn các ngôn ngữ tổng
quát, như LISP, Prolog... Vai trò của các
ngôn ngữ này có thể trở thành quan trọng hơn
để bổ sung cho các ngôn ngữ tổng quát, trong
quy trình tiến hoá về hướng các ứng dụng
tích hợp ngày càng rộng hiện nay.
2.2 Các mô hình
quy chiếu
Đi song song, và
để bổ túc cho các công cụ lập trình hiện đại,
cần nhưng không đủ để phát triển tốt đẹp những
hệ mềm lớn như loại dùng trong viễn thông ; tập
thể các công ty sản xuất và quản lý mạng viễn
thông đã từ lâu ngồi lại với nhau để xác định
những mô hình quy chiếu (reference
model). Đó là một thứ ngôn ngữ để mô tả rõ ràng
hơn ngôn ngữ thường, nhưng cũng không hoàn toàn
hình thức như ngôn ngữ lập trình, và thường được
minh họa bằng các hình khối ; chúng cho phép
hiểu giống nhau cú pháp và ý nghĩa của các thông
tin cần truyền qua các điểm quy chiếu (reference
points) được quy định giữa hai hệ thống. Việc
này cho phép chuẩn hoá các giao thức (protocol)
cần thiết trong viễn thông để gửi nhận thông tin
và để quản lý mạng.
Sáng tạo đầu
tiên là chuẩn OSI ( Open System Interconnection)
của tổ chức chuẩn quốc tế ISO (International
Organisation for Standardization) thành lập một
mô hình 7 tầng giao thức từ thấp (gần vật chất,
thấp nhất là việc truyền các bít qua giây điện)
đến cao. Mô hình này không được áp dụng hoàn
toàn trên thực tế vì nhiều lý do, ngoài một vài
áp đặt có tính hơi giáo điều (như nhất định phải
tuyến tính từ 1 đến 7), nó vừa quá đơn giản vừa
quá phức tạp so với thực tế. Tuy nhiên nó đã có
ảnh hưởng tri thức rất mạnh và là nguồn cảm hứng
cho nhiều mô hình quy chiếu khác.
Trong lãnh vực
viễn thông kể từ đó có khá nhiều mô hình quy
chiếu ra đời ; mỗi mô hình nhằm làm cơ sở cho
việc chuẩn hóa một kỹ thuật mạng hay một vấn đề
nào đó. Thí dụ như mô hình ISDN của mạng điện
thoại số, mô hình TMN nhằm vào việc quản lý các
mạng viễn thông, mô hình TINA dùng để phát triển
các ứng dụng viễn thông... Có thể nói các mô
hình này nhằm phục vụ việc thiết lập, bảo trì và
phát triển các mạng và dịch vụ viễn thông, một
mảng lớn của công nghệ thông tin, chúng tương
ứng với các tầng từ 1 đến 4 của mô hình OSI, và
không phải là chủ đề của bài này. Ở đây chúng ta
chỉ đề cập đến công nghệ tin học phân tán, tức
là phần trên của mô hình OSI, và như thế mô hình
quan trọng nhất hiện nay là OMA (Object
Management Architecture) và trong OMA thì bộ
phận nòng cốt là CORBA (Common Object Request
Broker Architecture), sau đây sẽ gọi chung cả là
CORBA cho gọn. Trước khi CORBA trở thành cơ bản
vì tiếp cận hướng sự vật được đại đa số trong
ngành CNTT chấp nhận, thì đã có nhiều mô hình
quy chiếu khác nhằm cụ thể hoá phần trên của mô
hình OSI, thí dụ như DCE (Distributed Computing
Environment), mà CORBA thừa hưởng khá nhiều. Ở
đây không có chỗ mô tả DCE ; cũng như không có
chỗ mô tả DCOM (Distributed Component Object
Model), một mô hình hướng sự vật và phân tán
khác của riêng Microsoft. Trái với CORBA là một
mô hình mở, DCOM khép kín trong các sản phẩm
hoàn toàn tuỳ thuộc Microsoft.
3. OMG, OMA
VÀ CORBA
OMG là một tổ
chức chuyên ngành vô vụ lợi, do 8 công ty quốc
tế thành lập tháng 5 năm 1989, trong đó đáng kể
là Hewlett-Packard và SUN, nhằm thiết lập một
khung cảnh khái niệm chung về hướng tiếp cận sự
vật phân tán, để có thể cho phép các hệ áp dụng
hướng sự vật, đã và sẽ được phát triển trên
những hệ điều hành và thiết bị khác nhau, có thể
trao đổi với nhau. OMG đáp ứng đúng nhu cầu
chung và có một phương pháp làm việc khá khách
quan, nên đã được hưởng ứng mạnh mẽ. Tới nay đã
có khoảng 800 (tức là hầu hết) tổ chức và các
công ti CNTT lớn trên cả thế giới tham gia.
Vấn đề muốn giải
quyết không đơn giản, và lại phải giải quyết
'giữa chợ ' huyên náo và đông người, cho nên
tiến bộ cũng chậm chạp. OMG theo con đường của
OSI-ISO : cùng nhau thành lập một mô hình quy
chiếu, và từ đó thỏa thuận dần về các chuẩn giao
diện và giao thức 3
. Sau gần 3 năm bàn cãi một số tài liệu có tính
giai đoạn (CORBA 1) được công bố năm 1992.
Nhưng, tuy rằng mục đích chính đã đạt là các
chương trình ứng dụng thì có thể mua từ nhiều
nguồn, sai lầm khá lớn của CORBA 1 là chỉ thoả
thuận về chuẩn giao diện mà đã để cho các giao
thức được phát triển tự do. Có lẽ vì một mặt các
tập đoàn sản xuất CNTT thoả thuận ngầm với nhau
lúc ấy là mỗi người giữ khách hàng của mình,
hay/và mặt khác họ không thống nhất được với
nhau về một kỹ thuật ORB duy nhất 4.
Hậu quả là trong một mạng cơ quan thì chỉ áp
dụng được CORBA giữa những máy cùng một hệ, và
hoàn toàn không thể đi ra ngoài, vì để trao đổi
với nhau các chương trình ứng dụng cần đến những
giao thức ở phía dưới.
Đến giữa 1996 ta
có một hệ thống tài liệu tương đối hoàn chỉnh
tuy chưa đầy đủ (CORBA 2). CORBA 2 phải sống với
những sai lầm của CORBA 1 nhưng đã đưa ra được
những biện pháp phụ trội cho phép các sản phẩm
tuân thủ CORBA 2 của các nhà sản xuất khác nhau
liên hệ được với nhau. Nhưng điều này cũng chỉ
hạn chế trong một mạng cơ quan, vì nếu đi ra
ngoài thì còn vấp phải một số vấn đề như an toàn
thông tin, kiểm tra chất lượng các sự vật ở
xa... Những vấn đề này, theo OMG, hiện nay đã
được giải quyết, và CORBA 3, dự kiến ra đời
trong năm 2000, sẽ là một tập hợp chuẩn đầy đủ,
mở rộng CORBA 2 để cho phép các ứng dụng hướng
sự vật cộng tác được với nhau trên phạm vi toàn
thế giới, qua mạng Internet.
CORBA là một mô
hình quy chiếu nằm ở tầng các chương trình sử
dụng mạng, nó coi như việc truyền tin qua mạng
được bảo đảm ; và chỉ thiết lập các chuẩn để
liên lạc giữa các phần phân tán của ứng dụng
(tương đương với các tầng 5 và 6 của mô hình
OSI). Tầm quan trọng của các chương trình phục
vụ tổng quát việc ứng dụng phân tán này thể hiện
qua việc nảy sinh thuật ngữ 'middleware', tạm
dịch là hệ giữa. CORBA như thế là một
chuẩn của hệ giữa, 'giữa' đây có thể hiểu là
giữa các bộ phận phân tán của một ứng dụng, hay
giữa tầng ứng dụng ở trên và tầng viễn thông ở
dưới. Có thể hình dung một cách giản lược CORBA
qua hình vẽ sau :
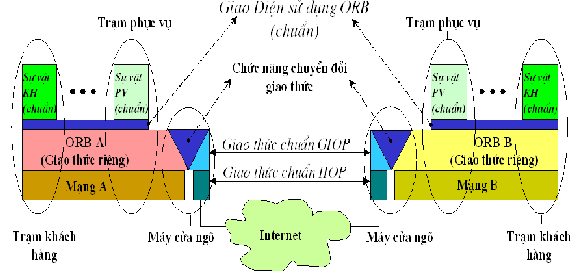
CORBA 2
và 3, trường hợp nối bằng Internet
Qua hình này ta
có thể ghi chú vài điểm sau :
CORBA 1 chủ
yếu đặc tả giao diện chuẩn cho phép sử dụng
các ORB (Object Request Broker). ORB gồm
những chương trình phân tán trong các máy
của mạng, quản lý tên và địa chỉ các sự vật
ở tầng ứng dụng, chúng liên lạc với nhau
bằng một giao thức riêng. Chức năng của ORB
là làm môi giới (broker) cho phép một sự vật
trong máy khách hàng yêu cầu sử dụng
(request) một sự vật trong máy phục vụ, mà
không cần biết nó ở đâu. Dĩ nhiên hai máy
này phải dùng cùng một hệ ORB và nằm trong
cùng một mạng truyền tin trong nghĩa cả về
thiết bị lẫn hệ điều hành mạng. Tầng ORBnằm
trên tầng vận chuyển (tầng 4, transport
layer), và các giao thức của ORB không cần
chuẩn hoá. CORBA 1 không nói gì đến các chức
năng chuyển đổi giao thức.
Một trạm
phục vụ cũng có thể chứa những sự vật khách
hàng của những trạm phục vụ khác, và trong
một ứng dụng không nhất thiết chỉ có những
quan hệ song phương.
CORBA 2 đặc
tả sự liên lạc và vận hành (interworking)
giữa các ORB khác nhau qua một giao thức
trung gian tổng quát gọi là GIOP (General
Inter-ORB Protocol). Giao thức này sẽ lại sử
dụng những loại giao thức 'đệm' khác nhau để
truyền tin qua các loại mạng khác nhau ;
trong đó đầu tiên và quan trọng nhất là giao
thức IIOP (Internet Inter-ORB Protocol), cho
phép sử dụng Internet. Việc sử dụng các loại
mạng trung gian khác đang được bổ túc dần.
Chức năng chuyển đổi các giao thức ORB đã có
sang giao thức GIOP là trách nhiệm của những
người đã sản xuất các ORB khác nhau.
CORBA 2
giải quyết được vấn đề của một cơ quan dùng
một mạng nhưng lại có hai nhóm máy mỗi nhóm
một ORB khác nhau A và B. Khi ấy hai máy
cửa ngõ nhập lại với nhau thành một trạm
chỉ có chức năng chuyển đổi giao thức thôi,
bởi không cần mạng trung gian. Nếu muốn hiệu
năng cao người ta có thể loại trừ luôn GIOP,
nhưng khi ấy phải viết thêm chức năng chuyển
đổi thẳng giữa các giao thức ORB A và ORB B.
Nhưng như
trên đã nói, trong thực tế CORBA 2 chưa đủ
đem lại độ tin cậy cho người dùng nếu thực
sự muốn nối 2 ORB bằng Internet hay một kỹ
thuật mạng khác. Nó chưa đặc tả nhiều chức
năng quan trọng trong đơn vị chuyển đổi giao
thức, đặc biệt là chưa giải quyết sự xung
đột với chức năng tường chặn lửa
(firewall) trong máy cửa ngõ. Người ta phải
đợi CORBA 3 mới hy vọng thành công.
Điểm rất
quan trọng và độc đáo của CORBA, một tiến bộ
rất lớn so với những đặc tả về giao diện
trước nó, là quan niệm về giao diện như sản
phẩm của một ngôn ngữ mô tả, vì vậy rất mềm
dẻo, rất tổng quát, mà lại rất dễ dùng. Ngôn
ngữ này gọi là IDL (Interface Definition
Language, ngôn ngữ mô tả giao diện) 5
, mỗi sự vật phục vụ cần có một mô tả bằng
IDL (hay nhiều, mỗi mô tả tương ứng với một
cách dùng khác nhau), được chép lại bên phía
sự vật khách hàng. Sau đó chương trình biên
dịch sẽ biến mô tả này thành hai chương
trình con, khách hàng một bên và phục vụ một
bên. Chính hai chương trình con này là giao
diện cho phép gọi tầng phục dịch ORB để liên
hệ giữa hai bên.
Ngoài CORBA
theo nghĩa hẹp ra, OMG còn có tham vọng đưa
vào mô hình OMA một số chuẩn và đặc tả khác
nữa mà ở đây không đề cập, đặc biệt ở trong
bản thân tầng ứng dụng (tầng 7 theo mô hình
OSI). Những cố gắng về kiến trúc này chưa có
gì ổn định, nó vừa bị xáo trộn bởi, vừa được
đơn giản hoá nhờ sự xuất hiện của Internet
và Java. Như đã nói trong phần dẫn nhập,
chính nhờ có một ngôn ngữ như Java và công
nghệ tác tử mà việc chuẩn hoá các giao diện
ở mức ứng dụng được đơn giản hoá đi rất
nhiều, vì nếu như trước thì mỗi ứng dụng cần
phải được cài đặt không những chương trình
phục vụ ở trạm phục vụ mà còn chương trình
khách hàng ở mọi trạm khách hàng. Nếu quan
niệm khách hàng có thể xuất hiện bất cứ lúc
nào ở khắp nơi trên thế giới và liên hệ với
trạm phục vụ qua Internet thì việc cài đặt
kiểu đó trở thành vô cùng tốn kém. Ngày nay
thì chương trình khách hàng là một tác tử
đơn giản được nạp từ xa thẳng vào máy của
người dùng khi cần.
Trên đây là một vài
đặc điểm cũng như tình hình hiện nay của CORBA,
'nhìn từ máy bay'. Không thể đi sâu thêm trong
phạm vi bài này vì đây là một chuẩn khá phức tạp
gồm mấy trăm trang đặc tả kỹ thuật.
4. W3C và chuẩn XML
4.1. Sơ lược
về XML
Với sự bùng nổ
của Internet thì tổ chức W3C có tầm quan trọng
đặc biệt. W3C hội đủ mọi công ty, đại học và cơ
quan hành chánh về CNTT lớn trên thế giới, cũng
như OMG. W3C có mục tiêu xác định những chuẩn
toàn cầu cho việc ứng dụng Internet ; và như thế
vai trò của OMG và W3C có phần nào trùng lặp. Ở
đây không trở lại vai trò kỹ thuật quyết định
của giao thức HTTP (Hyper-Text Transport
Protocol) và ngôn ngữ HTML trong hiện tượng bùng
nổ Internet trên toàn cầu, cũng như không mô tả
HTTP (công cụ vận chuyển, sử dụng giao thức TCP
ở phía dưới) và HTML (công cụ mô tả trang Web,
do HTTP vận chuyển), đã trở thành quen thuộc.
Nhưng không thể nói tới CNTT trên thế giới hiện
nay, dù chỉ dưới dạng hạn hẹp, mà không có vài
ghi chú về XML.
XML
(eXtensible Mark-up Language) là một chuẩn
do W3C quy định, nhằm tổng quát hoá và thay
thế chuẩn HTML, để cho phép thực hiện những
ngôn ngữ giao diện đặc thù cho từng phạm vi
hoạt động kinh tế, điều đó sẽ càng làm dễ
dàng hơn nữa việc viết các chương trình ứng
dụng với màn hình cho Internet.
Thực ra thì
HTML là một hình thức trình bày đặc thù của
một chuẩn cũ là SGML, có bổ túc thêm để cho
phù hợp với Internet, như thêm vào khái niệm
siêu liên hệ (hyper-link).
SGML là một
chuẩn rất đầy đủ và phức tạp để mô tả văn
bản trong việc in ấn, do tổ chức ISO thực
hiện từ đầu những năm 60, chủ yếu dùng trong
các chương trình điều khiển máy in lớn của
các nhà xuất bản chuyên nghiệp. Nó cho phép
mô tả các cấu trúc đặc thù của từng loại văn
bản bằng một tài liệu riêng đi kèm để xác
định kiểu văn bản (DTD, Document Type
Definition). DTD định nghĩa các nhãn ghi
chú (tag) 6dùng
để đánh dấu các câu, đoạn trong văn bản, và
xác định cú pháp (syntax) của tập hợp các
nhãn ghi chú đó. Có thể coi HTML như là SGML
không có DTD đi kèm, hay nói cách khác chỉ
có một DTD cố định duy nhất và ẩn tàng,
thích hợp với các trang nhện.
Những hình
thức trình bày đặc thù cho từng loại phát
hành khác nhau của cùng một văn bản, thí dụ
in ấn hay chiếu trên màn hình phải được xác
định bởi một tài liệu riêng khác, tờ thư
pháp7
(style sheet). Tài liệu này tuỳ thuộc thiết
bị ngoại vi, và xác định hình thức trình bày
của những câu đoạn, theo như các nhãn ghi
chú có trong DTD ; nó chỉ có ý nghĩa trong
việc trình bày thôi, nội dung văn bản hoàn
toàn độc lập với nó. Các tờ thư pháp của
SGML được viết bằng ngôn ngữ DSSSL (Document
Style Semantics and Specification Language,
ý nghĩa của thư pháp các tài liệu và
ngôn ngữ đặc tả thư pháp).
XML mở rộng
HTML bằng cách trở lại với SGML sau khi đã
đơn giản hoá 8
. Ấn bản XML 1.0 đã được phát hành từ tháng
Hai-1998. Tuy trong DTD còn thiếu nhiều thứ,
nhất là phần kiểm soát nội dung các trường
tuỳ thuộc nhãn ghi chú còn đang được bàn cãi
và phát triển thêm, nhưng XML đã được đưa
vào sử dụng mạnh mẽ. Những người làm tin học
trong mỗi ngành nghề hiện đang làm những đặc
tả DTD để dùng cho những tài liệu trong
ngành mình. Khi các công việc này hoàn chỉnh
thì việc thực hiện giao diện người-máy và
máy-máy qua liên mạng sẽ trở nên dễ dàng vì
mỗi người chỉ cần nắm những nhãn ghi chú
trong các DTD của ngành mình 9
. XML tương thích với HTML 10.
Ngôn ngữ mô
tả cách trình bày văn bản của XML được gọi
là XSL (eXtensible Style Language), thoát
thai từ DSSSL của SGML. XSL hiện nay đang ở
giai đoạn hoàn chỉnh, chưa có chuẩn chính
thức. Hy vọng sau đó sẽ có những chương
trình xử lý văn bản cũng dễ dùng và tốt hơn
hiện nay với đầu vào và đầu ra là XML. Một
việc trước mắt không khó khăn gì là làm
chương trình hoán chuyển hai chiều giữa dạng
XML và dạng riêng của các chương trình xử lý
văn bản đã có.
Nói chung,
một loại sản phẩm đang được nhiều nơi triển
khai là các chương trình phân tích cú pháp
XML (XML parser) để biến tài liệu XML thành
ra một điều gì khác có thể khai thác trong
những áp dụng đặc thù, chứ không phải chỉ xử
lý văn bản. Trong đó quan trọng nhất là biến
một tài liệu XML thành một sự vật mô tả tài
liệu, xử lý được bởi các ngôn ngữ hướng sự
vật (chẳng hạn để làm các cơ sở tài liệu,
documentation base, hay các kho URL...
). Hai chuẩn về các sự-vật-tài-liệu hiện
đang được bàn cãi là SAX (Simple API for
XML, giao diện lập trình đơn giản cho XML)
và DOM (Document Object Model, mô hình
của sự-vật-tài-liệu). Hiện đã có các
chương trình phân tích văn bản XML để cho ra
dạng SAX, các chương trình cho ra dạng DOM
thì còn ở mức thử nghiệm.
4.2. Lợi điểm
của XML
Không nên hiểu
XML một cách hạn hẹp như chỉ là một chuẩn để mô
tả văn bản có tính văn chương, dùng cho
màn ảnh hay in ấn và truyền được qua liên mạng.
Như thế cũng rất quan trọng rồi, nhưng tiềm năng
của nó vượt lên trên kích thước đó khá nhiều,
nếu ta lưu ý rằng tất cả những dữ kiện dùng cho
máy hay cho mạng truyền tin như các thông điệp,
các chương trình, các cơ sở dữ liệu... đều cần,
đến một lúc nào đó, hiện hữu dưới dạng con người
đọc được, nghĩa là dưới dạng một văn bản có
cấu trúc. Mà có thể nói định nghĩa cơ bản
của XML là như thế : một chuẩn mô tả các loại
văn bản có cấu trúc (xác định trong DTD) dưới
dạng con người đọc được. Từ đó, mặc dù một
số điểm bất tiện (nhỏ, và càng ngày càng không
quan trọng trước tiến triển kỹ thuật) như :
Văn bản XML
thường không hiện hữu một cách độc lập, mà
phải được đi kèm với một hay nhiều tài liệu
DTD mà nó sử dụng.
Văn bản XML
dài vì mang theo các nhãn ghi chú để dàn
trang, mô tả cấu trúc... lại thêm nữa mỗi
chữ cái dùng 16 bít theo chuẩn mới Unicode
thay vì 8 bít. Nhiều trường của cấu trúc
(fields, champs), như các con số đáng lẽ để
dưới dạng nhị nguyên, tiện cho máy và có
hiệu năng hơn, thì vẫn phải viết bằng chữ
cái.
XML chắc chắn sẽ
được sử dụng trong rất nhiều chuẩn của CNTT,
nhất là các chuẩn truyền tin ở mức ứng dụng và
trên mạng rộng, vì những thuận lợi rất lớn :
Một thí dụ
rất quan trọng đối với Việt Nam là : việc mã
hoá các chữ cái bằng 16 bít theo chuẩn
Unicode sẽ chấm dứt được tình trạng "thập
nhị sứ quân" hiện nay của các mã tiếng Việt
dùng 8 bít, với các khó khăn do nó gây ra
trong việc xử lý văn bản và việc truyền tin
trên mạng.
'chuẩn'
de facto của các văn bản Word theo
Microsoft, và do Microsoft lợi dụng thế mạnh
của mình tự ý thay đổi để bắt khách hàng
chạy theo và trả tiền nâng cấp mỗi lần, sẽ
không còn lý do tồn tại. Và như thế ai cũng
có thể sản xuất những chương trình xử lý văn
bản, vì mọi sản phẩm của các chương trình
này sẽ đều tương thích. Với nhiều loại
chương trình ứng dụng khác vấn đề cũng tương
tự, nếu có thể mô tả đầu vào và đầu ra bằng
XML.
Với XML
mạng Web sẽ thực sự là một mạng thông tin
quốc tế, vì chữ viết cho mọi nước đều sẽ
được thể hiện bằng một chuẩn thống nhất. Mọi
chương trình đều có thể được dùng tại khắp
nơi trên thế giới bằng cách thay đổi ngôn
ngữ giao diện một cách dễ dàng hơn hiện nay.
Một thí dụ
ảnh hưởng của XML lên trên việc xác định các
chuẩn : ngôn ngữ IDL của CORBA có thể được
viết lại một cách rất dễ dàng dưới dạng XML,
vì IDL cũng chỉ là một văn bản có cấu trúc
dưới dạng con người đọc được. Vậy thì các
chương trình khách hàng và phục vụ cũng có
thể trao đổi với nhau bằng ngôn ngữ XML với
một DTD đặc thù tương thích với IDL.
4.3. Đề nghị
chuẩn SOAP
Đó là ý đồ cơ
bản nằm đằng sau đề nghị chuẩn SOAP (Simple
Object Acces Protocol). Chuẩn này do Microsoft
đề nghị và đang được bàn cãi. Nếu so sánh SOAP
với GIOP và IIOP thì ta nhận thấy : SOAP có chức
năng tương tự với IIOP, nhưng thay vì dùng IIOP
để chuyên chở GIOP thì SOAP dùng HTTP để chuyên
chở XML với những chức năng tương tự và đơn giản
hơn GIOP :
Ưu điểm của
phương pháp này là sử dụng lại được những
công cụ và hệ thống đã có sẵn vì thế đưa vào
dùng rất nhanh chóng. Đặc biệt là không bị
xung đột với chức năng tường chặn lửa, vì
tường chặn lửa không ngăn chặn HTTP. Giải
pháp của GIOP/IIOP tuy cũng qua được tường
chặn lửa nhưng cần nâng cấp các tường chặn
lửa hiện có, vì dùng một chân cắm
(socket) cho giao thức TCP/IP khác với chân
cắm của HTTP. Một ưu điểm nữa của SOAP là vì
dùng XML nên có khả năng mở rộng dễ dàng nội
dung và cấu trúc của các thông điệp.
Nhưng các
ưu điểm này cũng là nhược điểm vì HTTP không
cho kết nối lâu dài (persistent connection),
chỉ có hỏi và trả lời là hết (chính vì thế
OMG đã dùng IIOP trên một chân cắm khác).
SOAP hiện nay mới dùng cho những ứng dụng
đơn giản, nếu muốn nối lâu dài thì cũng phải
xây dựng lên trên HTTP một khả năng nối lâu
dài giữa khách hàng và trạm phục vụ. Thêm
nữa vì SOAP chuyên chở thẳng XML nên dài
dòng hơn, chậm và tốn giải tần của mạng hơn.
Điều này không đáng ngại lắm, đáng ngại hơn
là mỗi lần các sự vật gọi nhau qua SOAP lại
phải thông dịch giao diện viết bằng XML,
hiệu năng sẽ rất thấp so sánh với IDL là một
ngôn ngữ biên dịch một lần rồi thôi.
Từ đó suy
ra, với tình trạng hiện nay, việc chọn lựa
XML/SOAP hay IDL(biên dịch)/IIOP tùy thuộc
tần số và cách thức liên hệ của các sự vật.
Tuy nhiên, đây là
những vấn đề còn đang được bàn cãi, triển khai,
và có thể thay đổi. Chưa có kết luận rõ ràng,
nhưng rất đáng theo dõi. Có lẽ hướng trong tuơng
lai gần là OMG và W3C phải cộng tác để có một
giải pháp toàn bộ giữ được cả ưu điểm của XML và
CORBA.
5. JAVA
Ngôn ngữ Java do
hãng SUN sáng tạo và phát triển từ đầu những năm
90, nó trở thành rất được ưa chuộng từ khoảng
bốn năm năm nay, nhờ ở một số đặc điểm hết sức
thích hợp với mạng Internet, hiện đã bùng nổ
trên toàn thế giới, và đưa tới yêu cầu phát
triển những ứng dụng cho Internet. Java là một
ngôn ngữ lập trình hoàn chỉnh 11
được thiết kế theo hướng sự vật và kế thừa có
nâng cấp của những ngôn ngữ lập trình đi trước
nó :
Về mặt cú
pháp, Java rất giống C++, ngôn ngữ lập trình
hướng sự vật phổ biến nhất hiện nay, nhưng :
Java loại
ra khỏi C++ những khả dụng (facilities) quá
mạnh nhưng khó và ít dùng, hoặc thừa về mặt
ngôn ngữ : không có kiểu dữ liệu cấu trúc
(structure) của C hay C++, vì có thể thay
thế dễ dàng bằng những sự vật đặc thù ;
không cho phép sự kế thừa nhiều lớp
(multiple inheritance), nhưng tạo ra khái
niệm 'lớp bên trong' (inner class) cho phép
thực hiện những chức năng tương đương trong
nhiều trường hợp một cách chặt chẽ (nhưng
cũng hơi nặng nề) hơn. Không cho phép thao
tác số học trên kiểu con trỏ
(pointer, mà Java gọi là handle), vì đây là
nguồn gốc của những 'con bọ ' không thể phát
hiện khi biên dịch...
Vì vậy đối
với những người lập trình chuyên nghiệp đã
quen với C hay C++ thì Java không linh động
và hiệu năng bằng C hay C++ để làm những
chương trình lớn và phức tạp. Đây chỉ là vấn
đề thói quen, vì tuy rằng với cùng chức năng
thì chương trình Java có thể dài và chậm
hơn, nó dễ hiểu và dễ chỉnh lý hơn. Đó lại
chính là điều quan trọng nhất trong những
chương trình lớn. Mặt khác thì Java còn cao
cấp hơn C++ ở nhiều mặt :
Đó là một
ngôn ngữ đa mạch (multi-thread), cho
phép thực hiện nhiều mạch song hành, cũng
như ADA hay nhiều ngôn ngữ 'thời gian thực'
khác. Đồng thời, với việc khởi động và đóng
các mạch hay/và sự vật thì ngôn ngữ Java
không có các lệnh xin và trả bộ nhớ, vì giả
thiết máy ảo Java (JVM, Java Virtual
Machine, xem sau đây) có bộ phận tự động
quản lý 12
bộ
nhớ.
Những đặc tính kể
trên có thể được coi như đã tổng hợp và rút kinh
nghiệm khá tốt những kỹ thuật cổ điển. Nhưng còn
đáng chú ý hơn, Java thêm vào những đặc thù mới
khiến cho nó đáp ứng được những nhu cầu của thời
đại là việc xử lý phân tán trên những hệ máy
không thuần nhất, dựa trên các mạng thông tin
hẹp, vừa hay rộng, và theo giao diện WWW của
Internet. Đó là :
Theo gương
PASCAL, Java là một ngôn ngữ nửa biên dịch
(compilation) nửa thông dịch
(interpretation). Các chương trình Java được
biên dịch thành một chuỗi giả lệnh
(gọi là byte code, tuơng tự như p-code của
PASCAL) ngôn ngữ giả lệnh này được một máy
ảo Java (JVM) thông dịch ngay thành ngôn ngữ
máy, khi chương trình hoạt động. Bất cứ loại
máy nào muốn sử dụng Java chỉ cần được cài
đặt một JVM, chuyện tương đối dễ dàng, và
khi đó thừa hưởng được tất cả các chương
trình viết cho Java, kể cả bộ biên dịch
Java.
Nhưng điều
đó không phải là lý do chủ chốt của thành
công, vì nếu thế thì PASCAL đã chiếm lãnh vị
trí thượng phong này từ hơn 20 năm trước.
Yếu tố khiến bây giờ khái niệm giả lệnh trở
thành không thể thiếu là công nghệ tác tử và
Internet : người ta có thể gửi tới bất cứ
máy nào trên thế giới có JVM (hay bộ thông
dịch Javascript) một ứng dụng nhỏ hay một
tác tử Java (hoặc Javascript) để được thực
hiện ngay tức khắc. Và đó là trường hợp của
hầu như tất cả các máy tính hiện nay, đặc
biệt là các máy PC với khả năng nhập mạng
Internet qua Internet Explorator của
Microsoft, hay Netscape Navigator.
Khi thực
hiện những lệnh máy từ nơi khác gửi đến có
nguy cơ là phần mềm của máy bị phá huỷ hay
thông tin bị chép trái phép từ những sai lầm
vô tình hay hữu ý. Vì thế bộ giả lệnh của
Java chỉ cho phép gửi đi một loại ứng dụng
nhỏ (applet) không được phép truy nhập vào
hệ thống dữ liệu của máy chủ nhà. Điều này
khác với các chương trình chính của Java,
cũng như việc các chương trình chính có thể
(và applet không thể) được biên dịch thẳng
ra ngôn ngữ máy để tăng hiệu năng nếu cần.
Để tránh
nguy cơ phần mềm bị phá huỷ thì kỹ thuật
nguy hiểm nhất, thao tác số học trên con
trỏ, đã bị loại. Còn lại một sai lầm hay xẩy
ra nữa là thao tác sai về các chỉ số (index)
của cấu trúc bảng, khiến cho chương trình có
thể viết ra ngoài bảng và phá hoại bộ nhớ
của máy. Đó là lý do tại sao JVM nhất thiết
phải kiểm điểm chỉ số mỗi lần truy nhập
bảng, trong khi thông dịch giả lệnh (cũng
như một lựa chọn cho phép nhưng ít khi được
dùng của trình biên dịch PASCAL). Với những
thận trọng 'di truyền' như thế thì không thể
viết được một ứng dụng con có thể làm hỏng
(về nội dung) bộ nhớ hay bộ đĩa của máy chủ
nhà. Tuy nhiên, khi biên dịch hay thông dịch
không có cách nào phát hiện một chương trình
phạm vào lỗi 'quay vòng vô hạn định' và từ
đó cũng có thể tiêu dùng tất cả tài nguyên
(resource) cho phép của máy và làm nó yếu đi
rất nhiều. Những người quen thâm nhập
Internet để đi tới những trang nhà
(home page) xa lạ đều có kinh nghiệm về hiện
tượng này và cách duy nhất là dùng các lệnh
ưu tiên của hệ điều hành để giết các ứng
dụng nhỏ loại đó. Hiện tượng này chắc sẽ còn
lan truyền do thiếu các 'Web-master ' có
trình độ, và ai cũng có thể tự mình học lấy
và làm 'Web-master '.
Thế nhưng,
giá phải trả cho những thận trọng nói trên
là : Java tương đối chậm hơn khá nhiều so
với những ngôn ngữ khác. Theo những đo đạc
đã được thực hiện thì nếu dùng JVM thuần tuý
(như bắt buộc đối với các applet) Java chậm
hơn C++ trên dưới 20 lần tuỳ theo ứng dụng.
Và nhiều tác giả cho rằng (chủ yếu vì việc
kiểm tra thường trực các chỉ số) các cố gắng
tối ưu hoá (như biên dịch thẳng ra ngôn ngữ
máy) cũng không thể nào làm cho Java chậm ít
hơn khoảng 3 lần so với C++. Mặc dù vậy trên
thực tế hiện nay phong trào phát triển bằng
Java vẫn ngày càng mạnh, và những người làm
tin học ứng dụng, trừ những nơi cần tính
toán khoa học kỹ thuật nhanh và nhiều, không
ai cho rằng sức xử lý của Java là một trở
ngại 13. Thực
tế là các trạm vấn tin đã quá thừa thãi sức
xử lý và trên các trạm phục vụ thì nói chung
cũng thế, chủ yếu người ta cần vận tốc truy
nhập vào các bộ đĩa. Nếu Java lại cho phép
thực hiện dễ dàng các hệ phân tán (dựa trên
CORBA, hoặc RMI, Remote Method Invocation,
một ORB riêng của SUN ) thì đã quá bù trừ
lại được điểm yếu của nó, do hiện tượng
thiết bị ngày càng rẻ so với nhân lực cần
thiết để phát triển các ứng dụng trong CNTT.
Cuối cùng,
đặc điểm hấp dẫn và hiện đại của Java là :
nó được tung ra cùng một lúc với cả một thư
viện chương trình đầy đủ để cho phép làm
việc với màn hình, coi ngôn ngữ HTML
(Hyper-text Mark-up Language) như là hệ
thống vào ra chủ yếu chứ không phải những
dòng chữ như các ngôn ngữ cổ điển khác. Tất
cả những gì ta thấy qua việc truy nhập
Internet hiện nay là được viết bằng HTML.
Sau này trong Java sẽ thay thế HTML bằng
XML.
6. Công nghệ tác tử
Thuật ngữ tác
tử thoát thai từ môi trường nghiên cứu về
trí tuệ nhân tạo, từ cuối những năm 80 người ta
đã nói tới các tác tử phân tán. Tác tử là
gì ? về lập trình có thể hiểu tác tử một cách
giản dị như là một sự vật hoạt động tích cực
một cách thường trực trong một máy tính nào đó,
chứ không phải như những sự vật thông thường chỉ
thụ động chờ đợi các thông điệp gửi tới nó rồi
mới khởi động một phương pháp nào đó do thông
điệp yêu cầu. Tích cực có nghĩa là tác tử
luôn luôn khảo sát khung cảnh chung quanh nó
(chẳng hạn bằng một quay vòng vô hạn định), và
có thể tự động phản ứng với những thay đổi chung
quanh nó. Nghĩa là tác tử có một trí tuệ
nhất định nào đó xác định bởi môi trường nó khảo
sát và những phản ứng có thể của nó, tuy rằng dù
sao chữ 'trí tuệ ' ở đây cũng chỉ là một
sự lạm phát danh từ như thường thấy trong tin
học14.
Khái niệm ấy khá
mơ hồ : ở mức độ thấp nhất môi trường đó được
giản lược vào bản liệt kê các thông điệp gửi tới
nó cùng với những phương pháp tương ứng nó phải
thực hiện ; như thế tác tử chỉ là một sự vật tin
học, không hơn không kém. Khó có thể xác định
mức trí tuệ cao nhất của tác tử, ở đây chỉ ghi
chú lại tình trạng tiến triển hiện nay với hy
vọng đem lại một ý niệm sơ lược về khả năng của
nó. Điều đáng chú ý là trừ những tác tử cố định
và độc lập, hầu hết các nghiên cứu và phát triển
về tác tử di động đều dựa trên chuẩn CORBA,
chuẩn XML và ngôn ngữ Java.
Mỗi tác tử có
hai kích thước không hoàn toàn độc lập với nhau
: đó là tính di động và tính có trí tuệ. Càng di
động cao càng ít có trí tuệ và ngược lại, nhưng
dĩ nhiên với tiến triển kỹ thuật thì vẫn có thể
tăng cường về cả hai kích thước. Một tác tử di
động thì khối lượng (đo bằng bít) của nó phải
nhỏ để dễ dàng truyền qua mạng, thêm nữa những
nơi tiếp nhận đều phải có một khung cảnh tiếp
đón chung (cơ-sở-cho-tác-tử-hoạt-động, = tác
sở 15) cho
phép tác tử hoạt động được, và nó lại phải hoạt
động với những giả thiết tối thiểu về nguồn tài
nguyên ở nơi tiếp nhận nó, do đó cũng phải tự
hạn chế chức năng. Hiện có nhiều hệ thống tác sở
khác nhau đang được nghiên cứu và phát triển, và
đề nghị về chuẩn cho các tác sở. Còn một tác tử
cố định thì không bị những hạn chế đó. Hiện
những tác tử có trí tuệ đều cố định, tuy có thể
hợp thành một cụm tác tử cộng tác và trao đổi
với nhau qua mạng rộng hay hẹp.
6.1. Tính di
động
Trong kích thước
di động có thể xếp tác tử vào các loại : cố
định, nạp từ xa được (telechargeable), và thực
sự di động. Các tác tử loại cuối này có thể tự
di chuyển đi nhiều nơi, còn các tác tử nạp từ xa
thì chỉ đi từ trạm phục vụ tới trạm khách hàng.
Một thí dụ
của tác tử cố định là tác tử giúp đỡ (help
agent) trong hệ văn phòng MS Office, một thí
dụ đơn giản trong đó tác tử chỉ tương tác
với những chương trình nằm tại chỗ một cách
thường trực nhưng kín đáo, nó chỉ nhảy ra
khi nhận thấy người dùng có vẻ đã thao tác
sai khi dùng một dịch vụ nào đó (về sự hữu
ích của nó thì xin miễn bàn, có người thích
có người không). Trong nhiều đề án nghiên
cứu hiện nay những tác tử có chức năng trí
tuệ cao nhất thường cố định và thường cộng
tác với nhau trong một nhóm nằm ở nhiều nơi
trên mạng.
Một thí dụ
về tác tử nạp từ xa là các rôbôt tìm kiếm
quy chiếu trong mạng Web của các hãng làm
dịch vụ tìm kiếm thông tin trên mạng như
Yahoo hay Altavista. Các rôbôt này thường
xuyên được gửi đi từ các cơ sở tài liệu rất
lớn của các hãng trên, tới các kho chứa các
trang Web, để đem về cập nhật mỗi ngày và
tích tụ cho tới nay hàng tỷ những URL và sắp
xếp chúng theo chữ khoá (keywords). Từ đó
phục vụ được sự tìm kiếm thông tin của hàng
trăm triệu người khách Internet trên thế
giới. Dĩ nhiên các applet hay cookies cũng
có thể được coi là thứ tác tử đơn giản nhất
trong loại này. Điều kiện để các tác tử nạp
từ xa hoạt động được là trong máy chủ nhà
phải đã được cài đặt JVM, máy ảo Java (hay
Javascript).
Hiện trên
thị trường chưa có những tác tử thực sự di
động. Việc thực hiện những tác tử loại này
khó hơn nhiều vì đó phải là một tập hợp ít
ra là hai tác tử trong đó một là cố định,
hợp tác với nhau trong mạng rộng 16
. Do đó ngoài việc đòi hỏi các nơi chấp nhận
chúng, ngoài các chức năng tác sở riêng
(trong đó dĩ nhiên có JVM), còn phải giải
quyết vấn đề di động của tác tử, tức là sẽ
phải nâng cấp CORBA 3 lên một mức khá cao để
thứ nhất là theo dõi, theo thời gian thực,
việc thay đổi địa chỉ ; và thứ hai là chuyên
chở được XML vì có phần chắc là ngôn ngữ
trao đổi giữa các tác tử (ACL, Agent
Communication Language) sẽ dựa trên XML. Đây
còn là chủ đề cho nhiều nghiên cứu và thử
nghiệm đang được tích cực tiến hành.
6.2. Tính trí
tuệ
Mô tả tính trí
tuệ của tác tử là điều không đơn giản, không có
một chỉ tiêu tuyến tính từ thấp tới cao. Dưới
đây là một vài khía cạnh khác nhau để đánh giá,
theo người viết bài tìm hiểu, danh sách này cũng
hơi khác nhau tuỳ tác giả. Như chúng ta sẽ thấy,
những đặc điểm về trí tuệ này thừa hưởng một quá
trình lâu dài những nghiên cứu và phát triển
trong ngành trí tuệ nhân tạo. Những khái niệm sẽ
được đề cập, tuy rằng cần được hiểu theo lưu ý
đã nói trên về sự lạm phát ngôn từ, chắc rằng sẽ
ảnh hưởng mạnh đến những phương pháp và ngôn ngữ
lập trình tuơng lai.
Có mục
tiêu : Tác tử, cũng như bất cứ chương
trình nào khác, được viết ra nhằm mục đích
giải quyết một vấn đề nào đó. Điều mới là
trong các chương trình cổ điển thì mục đích
giải quyết không được mô tả trong chương
trình, chương trình thực hiện nó nhưng không
nói tới nó. Trong tác tử điều này có thể
được mô tả hiển hiện thành mục tiêu rõ ràng
viết trong bản thân chương trình tác tử.
Điều ấy cho phép sử dụng những giải thuật
mềm dẻo dựa trên các tham số có thể thay đổi
với thời gian sau khi so sánh (tự động hay
không) kết quả với mục tiêu, nhờ ở tính
tự quản (autonomy) và tự thích nghi
(auto adaptation). "Tự quản và tự thích nghi
để tiến đến một mục tiêu" là một mô thức
(paradigm, nếp suy nghĩ và hoạt động
trong một ngành nào đó) thừa hưởng từ những
nghiên cứu về rôbôt.
Tự quản
: Tự quản trước hết có nghĩa là tác tử
tích cực hoạt động một cách thường trực,
không chỉ thụ động phản ứng trước những sự
kiện rời rạc xẩy ra với nó. Tác tử luôn luôn
xem xét môi trường chung quanh nó và có ý
thức về thời gian. Để làm được như thế
tác tử cần có bộ nhớ giữ lại nhiều trạng
thái biến đổi (và có thể tự biến đổi theo
thời gian) trong 'cuộc đời ' của nó, và có
thể một lúc nào đó tự động thực hiện một
điều cần thiết.
Tự thích
nghi : Một tác tử có trí tuệ phải biết
tự thích nghi để tự nâng cao khả năng với
thời gian. Muốn thực hiện điều đó thường là
bộ nhớ thường trực của tác tử được tổ chức
theo kiểu hệ chuyên gia (xem đoạn về bản
luận phía sau), có một cơ sở các dữ liệu
về sự kiện và một cơ sở các quy luật diễn
dịch (inference rules). Thêm vào đó là một
quy trình học hay tự học gồm những quy luật
đánh giá kết quả hành động quá khứ bằng cách
so sánh với mục tiêu. Người ta thấy ở đây
gia sản của các nghiên cứu về trí tuệ nhân
tạo và cách lập trình theo lôgích như trong
ngôn ngữ Prolog ...
Biết
trao đổi và thương lượng : Khi một tập
hợp nhiều tác tử cộng tác với nhau thì một
tác tử nào đó phải biết cách đi tìm một hay
những tác tử khác có chức năng mình cần.
Nhưng vì đối tượng cũng là một tác tử có khả
năng tự quản và độc lập cao nên không chắc
nó đã chấp nhận công việc nhờ cậy lúc
ấy ! trong ngôn ngữ trao đổi giữa hai bên
khi ấy phải có một thủ tục thương lượng
nào đó. Đây là điểm mới trong mô thức tác tử
không có trong mô thức sự vật, quan hệ giữa
hai sự vật có tính mệnh lệnh, quan hệ giữa
hai tác tử có tính ngang hàng hơn, tuy rằng
việc này có thể thực hiện bằng những công cụ
lập trình hướng sự vật.
Nếu các tác tử
là di động thì lại cần biết tìm địa chỉ cũng
như biết thích ứng với những giao thức cần
thiết cho việc liên hệ với địa chỉ đó. Người
ta còn muốn nghĩ tới việc thành lập những tổ
hợp tác tử một cách linh động trong đó các
tác tử có thể tham gia hay rút đi một cách
tự động. Điều này đặt ra những khó khăn mới
trên nhiều tầng giao thức.
- Có bản
luận 17:Ý
nghĩa của bản luận (ontology) trong
công nghệ tác tử là một hệ thống khái niệm
và ngôn ngữ biểu diễn và thao tác được trong
máy tính, chẳng hạn bằng một hay nhiều sự
vật tin học. Bản luận có hai phần : phần thứ
nhất ghi nhớ một cấu trúc thông tin nào đó
(hiện chưa thống nhất với nhau, có thể hiểu
như một sơ đồ thực thể - quan hệ, cổ
điển trong công nghệ cơ sở dữ liệu, hay như
một sơ đồ cơ sở hiểu biết (knowledge
base), cổ điển trong trí tuệ nhân tạo và có
khả năng biểu diễn mạnh hơn), cùng với những
phương pháp thao tác trên cấu trúc đó. Phần
thứ hai là những quy luật diễn dịch
(inference rules) đầu tiên, cũng còn gọi là
tiên đề (axiome) nhằm giới hạn và xác định
rõ những quan hệ được mô tả không đầy đủ
bằng sơ đồ. Bản luận chỉ là phần sơ đồ và
tiên đề mà thôi, nó được dùng để tác tử xử
lý những từ ngữ và dữ liệu ở đầu vào. Mỗi
tác tử có trí tuệ như vậy là một sự vật tin
học có mục tiêu và tự quản ; có phần ghi nhớ
bản luận của nó, tức là những khái niệm và
từ ngữ mà nó hiểu được, và những thao tác
trên hay/và dựa trên bản luận để biết tự
thích nghi và biết trao đổi, thương lượng.
Từ ngữ là phần
quan trọng trong bản luận, vì thế cần phân
biệt hai bản luận có thể là đẳng cấu
(isomorphe, từ điển toán học) nhưng dùng
từ ngữ khác nhau. Chính những thao
tác phát hiện ra các bản luận đẳng cấu, hoặc
hơi khác nhau nhưng có một phần đẳng cấu,
cho phép người ta hy vọng các tác tử biết
chấp nhận những khách hàng dùng ngôn ngữ tự
nhiên với những phong cách khác nhau. Đi xa
hơn nữa người ta hy vọng tự động dịch từ
tiếng nước này sang tiếng nước khác qua
suy luận cho đến bản thể nhờ ở sự phát
hiện và so sánh những khung cảnh ngữ nghĩa
tương đồng, mà không phải chỉ là dịch
một cách vô ý thức từng chữ một.
Nhưng mỗi bản luận tin học hiện nay chỉ là
một mảng nhỏ của hiện thực (tuy không rất
nhỏ như những sơ đồ thực thể quan hệ dùng
trong công nghệ cơ sở dữ liệu) một bộ
phận chủ yếu ở trong một đề mục chuyên
môn nào đó thôi. Không như 'bản thể luận'
trong triết học.
- Có cá
tính : Đặc điểm này nói về giao diện
giữa một tác tử với người dùng hay các tác
tử khác cùng cộng tác, và các chức năng bên
trong tương ứng. Một tác tử, khi đối thoại
với người dùng nó, có thể nhận ra phong cách
riêng của người ấy và đáp ứng một cách thích
nghi ; thí dụ đã có một tác tử thử nghiệm
phụ giúp vào việc mua bán chứng khoán, có
thể khi thì đề nghị những hành động 'chắc
ăn', khi thì đề nghị những việc mua bán
'phiêu lưu ' hơn, tuỳ khách hàng ; khách
hàng đây cũng có thể là những tác tử khác.
Đi xa hơn nữa người ta có thể quan niệm tác
tử có những 'cá tính' (personality) 18
khác nhau tuỳ trường hợp ; và cũng có thể sử
dụng những hệ diễn dịch dựa trên thuyết tập
hợp mờ để có những trả lời 'nửa nạc nửa mỡ
', hay 'ba phần đúng bảy phần sai ' và để
cho người dùng quyết định.
6.3. Một thí dụ
Một thí dụ của
tác tử có trí tuệ hay được nói đến là loại tác
tử tìm kiếm thông tin. Như hiện nay thì việc này
gồm hai phần : phần cố định nằm trong trạm chứa
kho quy chiếu URL để tìm theo nhu cầu, và phần
cố định nằm trong các chương trình đọc quét
(browser) như Netscape hay IE. Thế hệ hiện nay
của các chương trình phục vụ loại này nằm trong
kho của Altavista hay Yahoo thường chỉ chấp
nhận, từ chương trình đọc quét gửi đến, những
câu hay chữ chìa khoá với một quan hệ lôgích nào
đó giữa chúng với nhau, cộng thêm vài thông tin
để thanh lọc theo thời gian, ngôn ngữ v.v. ; sau
đó trạm phục vụ gửi trả lại một danh sách những
URL, thường khi vừa thừa vừa thiếu.
Thế hệ sắp tới
của các chương trình phục vụ tìm kiếm thông tin,
hiện đang được thử nghiệm tại nhiều nơi, sẽ là
các tác tử có trí tuệ tại cả nơi khách hàng và
phục vụ, tác tử khách hàng thích hợp với tác tử
phục vụ sẽ do trạm phục vụ nạp xuống máy khách
hàng, với điều kiện máy khách hàng là một tác sở
cho nó. Khi ấy tác tử của khách hàng sẽ trao đổi
với người dùng và trao đổi với trạm phục vụ để
chấp nhận những lệnh tìm kiếm 'thông minh' hơn.
Các tác tử còn có thể dùng bản luận để hỏi lại
người dùng cho rõ ý muốn, và tìm kiếm những khái
niệm, từ ngữ tương đương không cần có trong câu
hỏi v.v. để đem lại thông tin chính xác, ít
nhiễu và đầy đủ hơn.
Trong tương lai,
khi các tác sở của mọi nơi đã theo cùng một
chuẩn thì ta có thể tưởng tượng khách hàng gửi
một tác tử lưu động đến nhiều kho thông tin khác
nhau ; theo một lộ trình đến từng kho thông tin
để tự nó tìm kiếm, thanh lọc và loại trùng lặp ;
rồi lại mang theo kết quả đến nơi khác và tiếp
tục công việc cho đến khi xong lộ trình mới trở
về. Cách làm này giảm thông lượng cần đến trong
mạng, thay vì N lần đi và N lần về thì chỉ cần N
lần đi theo một vòng, thêm nữa mỗi lần thì thông
tin chuyển qua mạng cũng nhẹ hơn vì đã được
thanh lọc rồi (dĩ nhiên còn cái cộng thêm là
khối lượng thông tin của bản thân tác tử tự di
chuyển). Có thể suy ra dễ dàng là N càng lớn thì
cách đi vòng càng có lợi.
Kịch bản đó có
thể áp dụng cho nhiều sự phục vụ khác, chẳng hạn
trong thương mại điện tử : khách hàng có thể gửi
một tác tử với những chỉ tiêu nhất định về hàng
hoá, giá cả v.v. theo một vòng đi đến nhiều nơi
bán để chọn lựa mặt hàng và quyết định...
Đó không hoàn
toàn là tưởng tượng mà là chủ đề của nhiều đề án
đang được tích cực nghiên cứu về tác tử di động
và có trí tuệ.
6.4. Phạm vi
và điều kiện ứng dụng
Có một sự tăng
trưởng hỗ tương giữa công nghệ mạng truyền tin
và công nghệ tác tử. Một mặt mạng truyền tin
càng nhanh và có độ tin cậy cao thì tác dụng của
các tác tử càng được phát huy, mặt khác chính
những dịch vụ cơ bản của mạng thông tin cũng sẽ
được hỗ trợ bởi công nghệ tác tử. Cũng như có
một sự tăng trưởng hỗ tương khác giữa chất lượng
của công nghệ thông tin (mạng truyền tin cộng
với thiết bị tin học và phần mềm), và nhu cầu
của người sử dụng.
Với mạng
Internet hiện nay thì các dịch vụ mà công nghệ
tác tử có thể đáp ứng nói chung là do các tác tử
nạp từ xa thực hiện. Trong tương lai gần các tác
tử này có thể tăng thêm trí tuệ và làm tốt hơn
việc tìm kiếm thông tin trong không gian xibe
(ít nhiễu, nhanh và đủ hơn) bằng cách thanh lọc
thông tin theo đúng nhu cầu cá nhân của người
dùng. Các tác tử cũng sẽ được dùng trong việc tự
động giám sát các thông tin trong các đề mục yêu
cầu, và chỉ lưu ý người dùng khi có các sự cố
hoặc sự kiện đáng chú ý ; thí dụ như giám sát
thị trường, giám sát các tác phẩm, bài báo hay
thông báo chuyên ngành... chọn lọc và đề nghị
các tiết mục giải trí / văn hoá, chọn lọc và đề
nghị các đề tài du lịch, nơi nghỉ mát ...
Mặt khác công
nghệ tác tử cũng sẽ được ứng dụng vào trong bản
thân mạng thông tin để có thể quản lý mạng tốt
hơn, chẳng hạn bằng những tác tử di động giám
sát chất lượng và thông lượng của các nút và các
kênh trong mạng và đem về kịp thời những thông
tin báo động, thậm chí có thể tự thay đổi các
cấu hình của mạng thông tin để phản ứng nhanh
trước các sự cố. Đây là những đề tài nghiên cứu
có thể trở thành hiện thực trong tương lai không
xa.
Trong tương lai
xa hơn, nhưng có lẽ không quá một thập kỷ, vì đã
có những tiền đề kinh tế kỹ thuật rất rõ ràng,
tại Âu Mỹ mạng thông tin cho mọi người sẽ nhanh
hơn bây giờ hàng trăm lần, và như thế có thể
nghĩ đến những tác tử di động và có trí tuệ, đối
tượng nghiên cứu khá 'nóng' hiện nay. Chẳng hạn,
điều này có thể phục vụ cho những nhóm làm việc
chuyên ngành (trong bất cứ ngành nào) nằm ở khắp
nơi trên thế giới và người trong nhóm có thể tự
do di chuyển. Trong máy tính xách tay của mỗi
người sẽ có những tác tử độc lập phụ giúp trong
sinh hoạt riêng, cũng như có những tác tử phụ
giúp trong sinh hoạt nghề nghiệp và bản thân
chúng lại cộng tác với các tác tử khác của những
người trong nhóm. Những tác tử di động của trung
tâm quản lý sẽ có thể tìm đến nhân viên ở bất cứ
đâu để gửi/nhận thông tin dưới những dạng cô
đọng và được bảo vệ an toàn... Để ý là qua thí
dụ này ta thấy có hai loại tác tử di động, những
tác tử di động vì máy tính chứa nó di động, và
những tác tử di động vì bản thân nó tự di động
qua mạng, đó là loại nói đến trong bài này.
Những vấn đề của hai loại này không độc lập với
nhau.
Nhưng cần nêu
một vấn đề chủ chốt cần (và chưa) giải quyết
thỏa đáng ở mức chuẩn quốc tế : khó có thể hạn
chế các tài nguyên của một tác sở đối với tác tử
có trí tuệ vào những giới hạn quá hạn hẹp mà JVM
dành cho những ứng dụng con nạp từ xa như hiện
hay, tuy rằng như ta đã thấy, chỉ thế thôi cũng
còn chưa hoàn toàn ổn thoả. Như vậy thì cần tổ
chức kho dữ liệu và hệ điều hành của tác sở để
có phần công cộng và phần riêng tư, đây không
phải là cái gì khó lắm. Vấn đề thứ hai quan
trọng hơn là để bảo vệ an toàn các tác sở cũng
cần chỉ chấp nhận những tác tử 'tin cậy được'
đến thăm viếng mà thôi. Một điều thú vị là hướng
giải quyết cho yêu cầu này đã có : đó là dùng
những thuật toán của thương mại điện tử gồm chữ
ký điện tử và xác minh điện tử.
Một hướng phát
triển cần thiết và còn để ngỏ là cần đem vào một
ngôn ngữ như Java phương pháp lập trình lôgích
để cho phép thực hiện dễ dàng các hệ diễn dịch
(inference systems).
6.4 Công tác
chuẩn hoá
FIPA (Foundation
for Intelligent Physical Agent, tổ chức vì các
tác tử vật chất có trí tuệ) được thành lập năm
1996 với mục đích viết ra những đặc tả cho tác
tử trí tuệ thực hiện được trong ngắn hạn, đồng
thời với việc thực hiện những đề án cụ thể nhằm
vào việc thử nghiệm sự cộng tác giữa các tác tử
được sản xuất từ những nguồn khác nhau.
FIPA hoạt động
theo hai chiều. Hoạt động chiều ngang nhằm thực
hiện những chuẩn đặc tả các chức năng như : quản
lý các tác tử, ngôn ngữ trao đổi giữa các tác
tử, giao diện người-máy, việc tích hợp với những
phần mềm không phải tác tử, tính di động, an
toàn của tác tử, bản luận. Hoạt động chiều dọc
nhằm viết các hướng dẫn cài đặt các tác
tử trong một vài phạm vi sinh hoạt được chọn lọc
: phụ tá cho người du lịch, phụ tá cho hoạt động
văn phòng, phụ tá chọn lựa các giải trí và
truyền hình, quản lý mạng và kế hoạch phát triển
mạng. Các hướng dẫn cài đặt này được rút ra từ
những kinh nghiệm của các đề án thử nghiệm dẫn
đạo. Các đề án này theo sát và phản hồi lại cho
công việc làm chuẩn.
Cách hoạt động
như vậy khá hay, vì nó tạo ra sự qua lại giữa
hai chiều để đi đến những chuẩn thực tế. Nhưng
như vậy chắc là phải qua nhiều đợt thử nghiệm,
vì vậy không thể có nhanh các chuẩn ổn định cho
công nghệ tác tử. Có lẽ phải theo dõi và chờ đợi
hai ba năm nữa.
Mặt khác tổ chức
OMG cũng vừa thành lập nhóm làm việc cho chuẩn
mới gọi là MASIF (Mobile Agent System
Interoperability Facility, khả dụng cho phép các
tác tử di động cùng vận hành) nhằm tăng cường
CORBA để làm cơ sở dịch vụ viễn thông cho các
tác tử di động. OMG và FIPA hợp tác ( điều ấy
không có nghĩa không có những bàn cãi và đề nghị
khác nhau trên những chuẩn cả hai bên đều quan
tâm) chứ không cạnh tranh, FIPA đặt trọng tâm
vào khía cạnh trí tuệ, còn OMG coi nặng tính di
động.
7. Kết luận
CORBA, XML, Java
và tác tử đang trên đà hội tụ để tạo thành một
mô thức mới trong việc phát triển mạng thông tin
và dịch vụ CNTT trong thời đại Internet, mà đặc
tính là những ứng dụng dễ dùng, phân tán và di
động trong phạm vi toàn cầu. Hiện nay những khó
khăn về hiệu năng của mạng Internet cũng như của
các công nghệ này, cộng với tình trạng non trẻ
của chúng và của các chuẩn tương ứng, còn chưa
cho phép phát triển đại trà các ứng dụng. Nhưng
trong vài năm nữa các nghiên cứu và phát triển
sẽ chín mùi, chất lượng và thông lượng của mạng
thông tin sẽ tăng cao. Như thế các điều kiện sẽ
hội đủ để cho phép có những ứng dụng mới dựa
trên các công nghệ này, và có thể tiên đoán là
chúng sẽ đẩy mạnh những thay đổi trong sinh hoạt
kinh tế xã hội của con người nói chung, và lao
động trí óc nói riêng, trên cái đà mà Internet
đã khởi động.
Tuy nhiên các
công nghệ CORBA, XML, Java và tác tử chỉ là
những phương tiện và điều kiện. Nội dung của mỗi
ứng dụng tuỳ thuộc các vấn đề riêng của mỗi
ngành nghề và tổng cộng lại mới là khối lượng
công việc rất lớn và lâu dài cho thị trường phát
triển phần mềm. Mặt khác công nghệ tác tử cũng
còn cần nhiều tiến bộ cơ bản khác nữa trong công
nghệ thông tin nói chung, để trở nên hấp dẫn và
dễ dùng hơn : hiểu và viết ngôn ngữ tự nhiên,
ngôn ngữ lập trình (Java chưa hẳn là thiên đường
của người lập trình), nhận dạng và tổng hợp
tiếng nói, trí tuệ nhân tạo, cơ sở dữ liệu,
phương pháp luận phát triển hệ mềm, tổ chức và
quản lý mạng thông tin thế giới ...
8. Cảm tạ
Tác giả xin cảm
tạ ở đây sự khuyến khích, giúp đỡ bổ túc và
chỉnh lý bài này từ các bạn : Lê Phạm ngưng
Hương, Hồ tú Bảo, James Đỗ, Nguyễn Hoàng, Hồ văn
Tiến, Ngô trung Việt. Mọi sự khiếm khuyết thuộc
trách nhiệm riêng của tác giả.
9. Tham khảo
- Đầy đủ các
thông tin kỹ thuật về XML và liên hệ, cũng
như về tất cả các vấn đề liên quan tới
Internet, có thể tìm từ trang nhà của tổ
chức W3C.
Ngoài ra thì để
có cái nhìn tổng quát về XML xem bài trong
tạp chí Scientific American :
XML and the Second Generation Web,
May 1999
Về SOAP có thể
tham khảo
Microsoft hoặc ở
trạm
.
- Về Java, có
thể truy nạp một giáo trình rất tốt và cho
không trên mạng, của
Bruce
Eckel : Thinking in Java, ấn
bản 2.
Dĩ nhiên nguồn
thông tin dồi dào nhất về Java, tuy không
khách quan, nằm ở :
Sun và
Javaworld
.
- Về tổ chức
FIPA và các đặc tả trong ấn bản đầu, năm
1997, xin xem
. Ngoài ra có hai bài giới thiệu công nghệ
tác tử có thể đọc trên mạng :
Applications of Intelligent Agent,
và
A roadmap of Agent Research and Development.
Bài
trình bày có tính giáo trình về công
nghệ tác tử, khá dài và dưới dạng bảng
chiếu.
- Muốn biết
các nơi nghiên cứu về tác tử
. Về các
nghiên cứu cho cơ sở hoạt động của tác tử di
động, có bài tổng duyệt của Hens Krause ở ĐH
BK Lausanne : Technology review of
java-based Mobile Agent Platforms ; phần
tham khảo của bài sẽ dẫn đến những báo cáo
đáng kể. Có thể đọc sau khi chọn lựa từ
trang
liệt kê các báo cáo KH của ĐH BK Lausanne.
Khái niệm
Beegent
của Toshiba cũng đáng chú ý.
- Bài viết :
An Ontology Tool for Query Formulation in an
Agent-Based context cho thấy khá rõ
thế nào là một 'bản luận' tổ chức theo sơ đồ
thực thể-quan hệ.
Ngoài ra trang
nhà
có rất nhiều liên hệ tới những tài liệu về
công nghệ tác tử, đặc biệt nhiều mô tả các
ứng dụng.
1 Agent, tức là
người thừa hành (thường gửi đi xa) để làm
một việc được giao phó. Ở đây đề nghị 'tác
tử ', phỏng theo thuật ngữ 'toán tử ' trong
toán học. Nhưng cũng có thể dùng lại thuật
ngữ 'tác nhân' như thuật ngữ hoá học (agent
chimique). Dĩ nhiên những thuật ngữ dùng
trong bài này chỉ là tạm thời, trong khi chờ
đợi những thuật ngữ chính thức của một cơ
quan có thẩm quyền.
2 'Multimedia ' ,
gồm tiếng nói, hình ảnh, chữ viết. Người ta
còn hay dùng chữ media để nói chung về các
sản phẩm hay dịch vụ thông tin đại chúng :
báo chí, truyền thanh, truyền hình. Có lẽ
tốt nhất là giữ nguyên chữ media theo gốc La
tinh và phiên âm thành 'mêđia'. Một vài chữ
đã dùng để dịch 'multimedia' như 'đa môi
giới', 'đa môi trường', 'đa phưng tiện' ...
đều thấy chưa đạt, vả lại cả ba chữ này đều
có nghĩa quen thuộc rồi. Nếu nhất quyết
không muốn phiên âm thì ở đây đề nghị tân từ
'đa môi dạng' cho sát nghĩa hiện hành của
'media'.
3
Giao diện
(Interface) là các quy định về những trao
đổi trên-dưới của các tầng (giữa tầng i và
tầng i+1) nằm trong cùng một hệ thống ; và
Giao thức (protocol) là các các quy định về
những trao đổi theo chiều ngang giữa các
khối chức năng của cùng một tầng và nằm ở
những điểm khác nhau trong không gian, trong
một mạng thông tin. Đây là những thuật ngữ
của mô hình quy chiếu OSI mà OMG tuân thủ.
4 Đây là nhận định
của người viết bài này vì rất khó tìm ra
những phê phán khách quan, công khai và kịp
thời về OMG, một tổ chức rất lớn đủ sức để
thực thi chính sách "đẹp đẽ phô ra, xấu xa
đậy lại ". Chỉ khi nào chính OMG quảng cáo
ấn bản CORBA mới thì người ta mới hiểu
(ngầm) được những thiếu sót của cái cũ. Muốn
nắm bắt nhanh và đầy đủ các chuẩn cần tham
gia sinh hoạt chuẩn, khá tốn kém.
5 Trong Java cũng có
khái niệm Interface, và thực chất phần
Interface của Java và IDL là một, cú pháp
khác nhau rất ít. Không phải tình cờ mà hãng
SUN tác giả của Java cũng là một thành viên
năng động chủ chốt của OMG.
6 tag nghĩa đen là
một sợi chỉ, mẩu vải, mảnh bià... buộc thêm
vào cái gì đó để đánh dấu. Nhãn ghi chú của
SGML và XML là một hai chữ không có trong
văn bản, thay chỗ cho " ... " trong : chuỗi
< ... > ('< ' và '>' là hai dấu hiệu bao
bọc nhãn ghi chú).
7
Phương pháp này
được Microsoft dùng lại trong chưng trình
Word một cách giản dị và dễ dùng hơn, gộp
chung DTD + style sheet và cũng gọi là style
sheet. Style đây không có nghĩa là bút pháp
(phong cách hành văn), mà chỉ là cách xếp
loại chữ, kiểu chữ và khổ chữ trong văn bản.
Có lẽ chữ gần nhất là thư pháp, tức là cách
viết chữ, như viết thảo, viết chân phương...
8 SGML quá cồng kềnh
và XML không có tham vọng trở thành chuẩn
chuyên nghiệp của các nhà xuất bản. SGML
cũng đang được chỉnh lý lại để chấp nhận XML
như là một phần của nó.
9 Trong một vài năm
tới, tác dụng và một số vấn đề do XML mang
lại có thể lớn ngoài dự liệu những người làm
ra XML. Thí dụ : làm sao quản lí và sử dụng
hiệu quả khối lượng DTD đang tiếp tục căng
phồng lên trong thực tế.
10 Không hẳn hoàn
toàn, tuy nhiên, nâng cấp HTML (thành XHTML)
để tương thích với XML là rất dễ.
11
Khác với
Javascript, cũng tựa theo Java, nhưng do
Netscape và Sun cộng tác sáng tạo ; để cho
phép làm những 'applet' và 'cookie' (tác tử
nhỏ gửi từ một trang chủ Web tới người đọc)
dễ dàng hơn Java, nhưng về mặt lập trình thì
khả năng rất hạn chế và hiệu năng thấp.
12 Đây là con dao
hai lưỡi, vì nếu việc này tránh được một
loại lỗi thường xảy ra và khó phát hiện là
chương trình quên trả bộ nhớ, thì nó cũng
không thích hợp cho những hệ thời gian thực
gắt gao vì không biết lúc nào bộ vi xử lý bị
bận vì quản lý bộ nhớ. Hiện đang có những đề
nghị sửa đổi chức năng này.
13 Tuy nhiên, nếu
không để ý về mặt hiệu năng thì cũng có thể
bị thất vọng trong một thời gian. Điều cần
thiết cho người làm thiết kế hệ thống là
chọn lựa đúng đắn sau khi đã nắm rõ mọi khía
cạnh.
14 Đây không phải
làm một cách làm đáng chê, vì ta biết sự khó
khăn của những người nghiên cứu trong tin
học khi phải đặt ra những thuật ngữ cần
thiết để mô tả các sáng tạo của mình bằng
ngôn ngữ đời thường, qua so sánh với các
hiện tượng sinh học hoặc xã hội học. Từ 'lạm
phát' ở đây không có tính phê phán mà chỉ có
nghĩa đen : lạm phát tức là giảm giá trị .
Vấn đề thực sự là khi người ta dùng một từ
thông tục cho một khái niệm kỹ thuật thì ý
nghĩa của nó, vì hạn hẹp hơn, phải được xác
định rõ ràng hơn. Thí dụ như thuật ngữ 'bộ
nhớ ', ai cũng biết rất rõ nó chỉ định cái
gì. Việc phần lớn các khái niệm của công
nghệ tác tử không được xác định rõ ràng chỉ
chứng tỏ là công nghệ này còn rất non trẻ
(so với tham vọng). Vì vậy không nên cho nó
là cái gì ghê gớm.
15 Agency, trạm đón
tiếp có đủ các dịch vụ mà tác tử cần đến,
tạm dịch là tác sở, cũng có thể là cơ sở tác
tử, nhiều tác giả dùng chữ platform, cơ sở
hoạt động, có ý nghĩa chung hơn, chỉ một hệ
thống có cài đặt các dịch vụ mà một loại
chương trình ứng dụng nào đó cần đến.
Platform dùng lại ngôn ngữ chính trị, đó là
cơ sở chính trị để hoạt động của một tổ
chức.
16
Nếu mạng hạn hẹp
thì dễ hơn, nhưng có lẽ phạm vi ứng dụng của
các tác tử tự di động sẽ thu hẹp ; như chẳng
hạn trong một thuật toán phân tán trong cụm
máy tính, một tác tử có thể tự đi tìm máy
tính còn tài nguyên nhiều nhất để hoạt động.
17 Tập thể nghiên
cứu về tác tử dùng thuật ngữ 'ontology ' ,
có nghĩa triết học là 'bản thể luận ' , một
khái niệm rất cơ bản và cổ điển, nhưng cũng
khác nhau tuỳ triết gia ! Sự lạm phát này
không thể chấp nhận được, nó thể hiện một
tình trạng thiếu văn hoá đáng phàn nàn. Vì
thế đề nghị chữ 'bản luận ', theo từ điển
Hán Việt của Đào duy Anh là : 1) 'bộ phận
chủ yếu ở trong một đề mục', 2) 'suy luận
cho đến bản thể ' . Cả hai nghĩa đều sát với
ý nghĩa ontology thực sự của các 'trí thức
nhân tạo'. Thế cũng là lạm phát, nhưng khiêm
tốn hơn.
18 Đây cũng là hệ
luận của việc các tác tử có bản luận và biết
thao tác trên bản luận : sơ đồ hiểu biết và
tập hợp những quy luật diễn dịch của một tác
tử, tương ứng với một chủ đề nhận ra được,
có thể thay đổi (hay có một sơ đồ con và một
tập hợp tiên đề con dùng được) để thích hợp
với một phong cách hay một ngôn ngữ nào đó
của người (hay tác tử khác) đối thoại với
nó.
|