|
Những bài cùng tác giả
Bệnh Thiếu Máu do có Hồng Huyết Cầu Lưỡi Liềm (Sickle Cell Anemia). Một
trường hợp Sử Dụng Công Nghệ Thông Tin Sinh Học Phân Tử trên Mạng để tìm
hiểu và phân tích.
Lời nói đầu:
 Đây
là bài dịch của một bàt tập đăng trên mạng của Biology Workbench dành cho
sinh viên sinh hóa thực tập dùng các dữ liệu cùa National Center for
Biotechnology Information (NCBI) để nghiên cứu sinh học phân tử, một môn học
rất đang được phát triển ngày nay. Bài tập này đã dùng trường hợp của bệnh
hồng huyết cầu lưỡi liềm (sickle cell anemia) để tìm hiểu sự biến đổi của
gene diễn giải (coding) cho phân tử hemoglobin, chất protein nồng cốt cho
hồng huyết cầu, và sự biến đổi này đã là nguyên nhân chính gây ra bệnh này.
Bài dịch đã được hai chuyên viên sinh học là Phạm Thanh Phong
(phamthanhphong@aim.com) và Cao Xuân Yến (xuanyen611116@gmail.com) dùng mạng
Internet kết nối ở Việt Nam để thực nghiệm và chứng minh là bài tập có thể
thực hiện được . Mặc dầu có vài sự thay đổi nhỏ trong phiên bản mới của
Biology Workbench so với phiên bản đưọc dùng trong bài dịch này, nhưng nó
không ảnh hưởng đến kết quả của bài tập. Điều quan trọng là những lời chỉ
dẫn và kết qủa có được ở từng giai đoạn viết trong bài tập phải triệt để
tuân hành. Riêng phần Protein Explorer (phần VI) đã được thực hiện với
Internet Explorer 6. Như đã chỉ dẫn trong bài, phần VI đã dùng thêm phần mềm
Chime (tải dùng miễn phí) để thực tập, mặc dầu cũng có dùng phần mềm JMOL.
Dịch giả thành thực cám ơn sự đóng góp của hai chuyên viên sinh hóa nói
trên. Đây
là bài dịch của một bàt tập đăng trên mạng của Biology Workbench dành cho
sinh viên sinh hóa thực tập dùng các dữ liệu cùa National Center for
Biotechnology Information (NCBI) để nghiên cứu sinh học phân tử, một môn học
rất đang được phát triển ngày nay. Bài tập này đã dùng trường hợp của bệnh
hồng huyết cầu lưỡi liềm (sickle cell anemia) để tìm hiểu sự biến đổi của
gene diễn giải (coding) cho phân tử hemoglobin, chất protein nồng cốt cho
hồng huyết cầu, và sự biến đổi này đã là nguyên nhân chính gây ra bệnh này.
Bài dịch đã được hai chuyên viên sinh học là Phạm Thanh Phong
(phamthanhphong@aim.com) và Cao Xuân Yến (xuanyen611116@gmail.com) dùng mạng
Internet kết nối ở Việt Nam để thực nghiệm và chứng minh là bài tập có thể
thực hiện được . Mặc dầu có vài sự thay đổi nhỏ trong phiên bản mới của
Biology Workbench so với phiên bản đưọc dùng trong bài dịch này, nhưng nó
không ảnh hưởng đến kết quả của bài tập. Điều quan trọng là những lời chỉ
dẫn và kết qủa có được ở từng giai đoạn viết trong bài tập phải triệt để
tuân hành. Riêng phần Protein Explorer (phần VI) đã được thực hiện với
Internet Explorer 6. Như đã chỉ dẫn trong bài, phần VI đã dùng thêm phần mềm
Chime (tải dùng miễn phí) để thực tập, mặc dầu cũng có dùng phần mềm JMOL.
Dịch giả thành thực cám ơn sự đóng góp của hai chuyên viên sinh hóa nói
trên.
Giới Thiệu
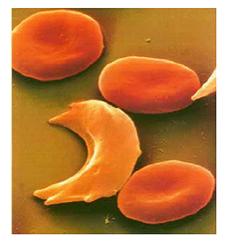
Sickle cell anemia là bệnh di truyền trong đó bệnh nhân trông rất bình
thường ngoại trừ xanh xao thiếu máu do hồng huyết cầu
bị xẹp lại trông như lưỡi liềm vậy. Nguyên nhân sự kiện này là do phân tử
hemoglobin bị biến đổi (mutation) ở một aminoacid. Phân tử hemoglobin là một
protein gồm có 4 xâu polypeptides; hai alpha-globin
và hai beta-globin. Phân tử này là thành phần chính của hồng huyết cầu dùng
để vận chuyển oxygen (O2) từ phổi đến các cơ quan khác của cơ thể
và trao đổi với than khí carbonic (CO2), chất thải của dinh dưỡng
(Kreb’s Cycle) để đem trở lại phổi. Sự thay đổi của aminoacid xảy ra ở một
chuỗi beta-globin làm thay đổi cấu hình (configuration) của phân tử
hemoglobin khiến cho phân tử không thể gắn vào oxygen và dẫn đến sự vận
chuyển oxygen nói ở trên trở lên vô hiệu quả. Hậu này quả là hồng huyết cầu
của bệnh nhân này kết tụ lại thành chùm dây (fibrous threads) và không thể
di chuyển qua các mạch máu nhỏ (narrow capillaries) một cách dễ dàng, dẫn
đến kết quả là thiếu máu di chuyển đến một phần cơ thể và làm bệnh nhân cảm
thấy rất đau đớn.
Bài tập này đặc biệt chú ý đến sự biến đổi (mutation) của hemoglobin, vì do
đó là nguyên nhân chính dẫn đến bệnh gây ra sự đau đớn này. Sự thay đổi này
bắt đầu từ biến đổi của gene (DNA) mà nó dùng để dẫn giải (coding) cho
protein beta-globin. Điều này được giải thích như sau: Từ sự biến đổi một
nucleotide trên chuỗi DNA cũng sẽ dẫn đến sự thay đổi của một nucleotide
tương ứng trên phân tử mRNA (G-C, A-U). Mỗi bộ 3 nucleotides trên mRNA lập
thành một codon mà nó chọn ra một tRNA có codon- Amino-Acid (AA) tương xứng
và đặt vào chuỗi AAs (peptide) đang trên đường tạo lập. Nếu một nucleotide
trên codon của mRNA bi thay đổi thì nó sẽ dẫn đến chỗ có một AA sai được gắn
vào sai vi trí của peptide, và đó là trường hợp của chuỗi beta-globin trong
bệnh sickle cell anemia được chọn ra ở đây để thực tập.
Mục đích của bài thực tập này gồm hai phần. Thứ nhất là bạn sẽ học được cách
tìm trên internet các dữ liệu (data bases) chứa chấp và sắp xếp các chuỗi
DNA hay các chuỗi protein. Bạn sẽ học được cách tìm kiếm, sắp đặt, và thay
đổi thứ tự của chuỗi theo ý muốn. Bạn cũng có thể học cách nhìn các phân tử
proteins trong không gian 3 chiều dựa trên các proteins mà bạn kiếm được
trong các data bases nói trên. Trong phần thứ hai các bạn sẽ dùng các
databases nói trên để học về các khía cạnh sinh học phân tử của bệnh sickle
cell anemia. Để làm được các việc này chúng ta sẽ dùng hai phần mềm quan
trọng gọi là Biology Workbench và Protein Explorer. Phần mềm Biology
Workbench được thiết kế để giúp sinh viên tìm kiếm và phân tích các chuỗi
DNA hay protein theo ý muốn. Phần mềm protein explorer sẽ giúp nhìn phân tử
trong không gian 3 chiều. Các bạn sẽ dùng protein explorer để khảo sát sự
biến đổi của beta-globin đã thay đổi hình dạng của phân tử này và dẫn đến
bệnh thiếu máu.
Phần I:
Ghi danh để sử dụng (mở account) cho Biology Workbench. Muốn vậy, bạn hãy
vào trang internet: http://workbench.sdsc.edu. Sau đó, ta sẽ làm ”set up
free account” để có được user name và password. Khi ta đã login được rồi thì
sẽ thấy trang đầu như sau:

Sau khi kéo đến cuối trang bạn sẽ được chọn mầu nền (background) mà bạn nên
chọn lấy mầu hồng để cho xem được rõ ràng sau này. Bạn sẽ bấm chuột vào nút
“session tools” để bắt đầu.
Chương trình mới bắt đầu từ trang có các tiêu đề như sau:

Bạn nhấn chuột vào nút “New Session Tools” , sau đó là “Run”.
Bạn tạm đặt tên cho session description là Sickle Cell Anemia và đánh tên
này vào ô sau đây:

Sau đó trang Sickle cell anemia xuất hiện. Bạn có thể lựa chọn giữa trang
“Default” và trang này. Chú ý là ta luôn luôn về trang Sickle Cell Anemia
này trong bài tập.

Trong các phần sau chúng ta sẽ học cách tìm kiếm và phân tích các chuỗi DNA
hay protein, rồi nhập chúng vào phần mềm Workbench. Chúng ta dùng chuột bấm
vào hộp ô “Nucleic Tools” trên đầu trang để vào chương mục sử dụng nucleic
acid tools. Bắt đầu chúng ta thấy ô “empty” hiện ra, chứng tỏ chưa có chuỗi
protein nào đã được kết nạp vào. Khi chúng ta nhập một chuỗi qua “cut-past”
từ một kho dữ liệu (databases) thì chữ “empty” sẽ biến mất và thay vào đó là
những chuỗi DNA mà chúng ta đã muốn kết nạp.
Phần II.
Kết nạp các chuỗi từ “Nucleic Acid Sequence Databases”
Trong phần này chúng ta sẽ học cách nhập các chuỗi DNA từ các kho dữ liệu.
Như đã nói ở trên, chúng ta muốn khảo sát “gene” của beta-globin, và đâu là
sự biến đổi (mutation) dẫn đến bệnh thiếu máu Sickle Cell Anemia.
Để làm được công việc trên, chúng ta dùng chuột để kéo thư mục tìm kiếm
xuống tới hàng chữ “Ndjinn-Multiple Database Search” như hình chỉ dưới đây,
rồi bấm vào ô “Run” ở phía dưới.
Trong trang kế tiếp thì có một danh sách các kho dữ liệu mà chúng ta có thể
chọn lựa. Trong ô tìm kiếm chúng ta đánh chữ beta-globin và trong ô bên cạnh
chúng ta dùng “Show All Hits” để lấy tất cả kết quả tìm được. Sau đó chúng
ta bấm vào ô “Search”.

Tiếp đến chúng ta sẽ thấy một trang liệt kê một lô các databases khác nhau,
chúng chia ra làm 2 nhóm: Một nhóm gồm các chuỗi DNA của các cơ thể khác
nhau (vi dụ GBPHG là kho dữ liệu của các vi khuẩn, GBPLN là kho dữ liệu của
thực vật, nấm, và rong biển. Nhóm thứ hai gốm các chuỗi DNA của toàn thể một
cơ thể đặc biệt nào đó. Thí dụ “Mthe” là dữ liệu của toàn thể vi trùng
Methanobacterium thermoautotrophicum.
Bởi vì ở đây mục đích của chúng ta là tìm các chuỗi DNA (beta-globin gene)
cho con người, do đó chúng ta đánh dấu √ vào ô GBPRI (geneBank Primate
Sequences)

Bấm chuột lùi xuống để nhìn thấy ô “Search” để bấm vào đây. Bạn sẽ thấy kết
quả của sự tìm kiếm hiện ra trong trang này. Ở thời điểm này có ít nhất 293
“hits” do sự tím kiếm của “beta-globin” genes. Số này sẽ thay đổi hàng ngày
do các chuyên gia bỏ thêm vào. Từ kết quả này ta biết được thứ tự
“nucleotides”của chuỗi DNA trong ‘gene” của beta-globin của người khoẻ mạnh
bình thường. Đó là chuỗi “gbprt29436-human messenger rna for beta-globin”
(bạn có thể phải kéo chuột xuống để thấy hàng chữ này) .

Bạn hãy nhấn chuột để “highlight” (nét đậm) rồi bấm chuột vào ô “import
Sequence(s) ở trong hộp ở cuối trang như sau:

Sau đó thì chuỗi DNA (beta-globin gene) được nhập vào trang “Nucleic Tools”
của phần mềm Workbench.
Phần III.
Tìm chuỗi biến đổi (mutant) của beta-globin gene: Dùng phần mềm BLAST.
Như đã nói ở trên, chúng ta đã tìm ra chuỗi DNA của beta-globin trên gene
binh thường. Bây giờ chúng ta dùng nó để tìm ra chuôi DNA của beta-globin
trong gene bị bệnh thiếu máu Sickle Cell Anemia. Bởi vì chúng ta đã biết hai
chuỗi DNA này chỉ khác nhau ở một nucleotide (single base), do đó có thể
dủng chuỗi DNA bình thường đã có đễ đi tìm những chuỗi DNA tương tự
(homology) với nó. Phần mềm dùng để tìm những chuỗi DNA tương tự được gọi là
BLAST.
Hãy kéo chuột xuống tới phần sử dụng gọi là “BLASTN Compare a NS to a NS
DB”. (Đây là viết tắt cho “Compare a Nucleic Acid Sequence to a Nucleic Acid
Sequence Database”.) và chọn phần này bằng cách nhấn chuột vào đó để nét đậm
hiện ra, sau đó để ý rằng ở phần cuối của hộp ô chữ có chữ GBPRI:29436 Human
messenger RNA for beta globin với dấu √ ở phía trước. Bấm chuột vào ô nút
“Run”. Chúng ta sẽ thấy một trang mới hiện ra trong đó có nhiều sự chọn lựa
khác nhau. Trong phạm vi của bài tập này chúng ta chỉ cần để ý đến phần so
sánh giữa các chuỗi DNA trong con người, do đó chúng ta bấm chuột vào phần
“GenBank Primate Sequences” và sau đó bấm vào nút “Submit”. Sau đó chúng ta
sẽ có một trang mới với kết quả hiện ra do sự tím kiếm BLASTN.

Chú ý rằng hàng đầu tiên của kết quả chính là chuỗi mà ta đã bắt đầu hỏi,
tức là chuỗi của beta-glodbin của người bình thường. Sau đó là những chuỗi
gene tưong đồng gần nhất có diểm số cao (cột score hits). Điểm số mà cao hơn
400 thường chỉ định là sự tương đồng cao. Tuy nhiên, để có kết quả có thể
chắc chắn hơn thì chúng ta nhìn sang cột ở bên phải với chỉ số “E value”.
Chỉ số E Value
Chỉ số E (Expect, uớc lượng) là con số dùng để xếp hạng thứ tự ưu tiên trong
sự tím kiếm. Chỉ số này thực ra là con số uớc luợng có được do cách tính sác
xuất thống kê, nó dựa trên số lần tương đồng giữa các chuỗi nucleotides khi
so sánh với nhau, xảy ra một cách ngẫu nhiên và có cùng cỡ (số nucleotide
bases, kb) nào đó. Chỉ số E thay đổi từ 0,1 đến 10, với số càng nhỏ thì sự
tương đồng càng cao. Chỉ số 0 có nghỉa là hoản toản giống nhau (zero cơ hội
giống nhau do sự ngẫu nhiên) . Vậy bây giờ là lúc ta phải quyết định xem
chuỗi DNA nào là chuỗi có sự biến đổi so với chuỗi beta-globin bình thường.
Như đã nói ở trên, chúng ta biết là sự biến đổi của beta-globin gene này chỉ
xảy ra ở một nucleotide (gọi là single point muatation) mà thôi, vì vậy hai
chuỗi DNA này phải có sự tương đồng rất cao. Dựa trên kết quả có được từ
trang BLASN, chúng ta sẽ dù ng chuôt đêể đ âậ m né t “highlight” một số kết
quả có điểm “score hits” cao hay chỉ số E value rất thấp (lẽ dĩ nhiên trừ
hàng đầu ra). Sau đó chúng ta dùng chuột nhấn vào nút “Show Records” để có
được những kết quả của những chuỗi DNA mà chúng ta đã “highlight”. Chúng ta
sẽ nhấn chuột và kéo xuống đến phần “Records” cho đến khi tìm thấy hàng chữ
“beta-globin mutant. Chú ý rằng chúng ta muốn tìm sự biến đổi của chuỗi DNA
gây ra bệnh Sicklel cell anemia, do đó trong kết quả tìm kiếm có chữ
“sickle”, điều này chứng tỏ là đây là chuỗi DNA chúng ta muốn tìm kiếm.

Một khi bạn đã dịnh được mã số của chuỗi gene này rồi thì bạn ghi số này
xuống (mã số GBPRI:183944), sau đó bấm vào nút “Back” (trên mạng Internet
Explorer) để trở về trang BLASTN với những kết quả của sự tìm kiếm. Bạn sẽ
chọn kết quả với hàng chữ “mutant beta-globin” với mã số GBPRI:183944 như đã
nói ở trên và bấm chuột vào hàng chữ này (bỏ những hàng chữ khác mà bạn đã
chọn (highlight) trước đây. Sau đó bạn dùng chuột để kéo xuống cuối trang và
bấm vào nút “Import Sequence(s)”. Chuỗi gene biến đổi của beta-globin sẽ
được tải vào trang chủ của “Nucleic Tools”. Bây giờ là thời điểm chúng ta sẽ
tìm ra vị trí của nucleotide thay đổi và đã gây ra bệnh thiếu máu và rất đau
đớn này.
Phần IV:
Sắp xếp hai chuỗi DNA để so sánh: Sử dụng phần mềm CLUSTALW.
Để so sánh hai chuỗi nucleic acid thì chúng phải được sắp xếp song song trên
dưới lẫn nhau. Chúng ta có thể thực hiển được điều này bằng phần mềm
CLUSTALW. Sự sắp xếp hai chuỗi song song trên dưới lẫn nhau sẽ dựa trên
những đoạn nucleotides giống nhau của hai chuỗi. Phầm mềm Biology Workench
sẽ làm công chuyện đó bằng những phương thức toán học để tìm ra những đoạn
DNA giống nhau này và tự động sắp xếp chúng song song với nhau theo thứ tự
trên dưới mà chúng ta có thể kiểm soát được. Nhờ đó những nucleotide(s)
không giống nhau cũng có thề nhìn thấy được và xác định vị trí của sự biến
đổi của gene đã xảy ra.
Để phân biệt được các đoạn nucleotides giống nhau hay khác nhau thì phần mềm
đã dùng mầu sắc khác nhau để phân biệt, với mầu xanh da trời ở những vùng
rất giống nhau hay mầu xanh lá cây cho những vùng hơi khác nhau….
Để làm công việc so sánh chúng ta hãy dùng chuột kéo xuống hộp menu rồi bấm
vào hàng chữ “CLUSTALW-Multiple Sequence Alignment”, sau đó chọn hai
chuỗi beta-globin với mã số
GBPRI:183944 và GBPRI:29436
và bấm nút chuột vào ô “Run"

Một trang mới hiện ra với những sắp xếp thông số có thể chọn lựa được, tuy
nhiên chúng ta không cần thay đổi những thông số này, vì vậy hãy dùng chuột
bấm vào ô nút “submit”. Công việc này sẽ dẫn đến một trang mới với hai chuỗi
nucleic acid sắp xếp song song với nhau.
Trong hai chuỗi hiện ra, thỉnh thỏang chúng ta tìm thấy những chữ “Y” hay
“N”. Chữ “Y” có nghĩa là ở chỗ này thì nucleotide có thể là T (thymidine)
hay C (cytosine) mà không thể xác định được, còn chữ “N” thì có nghĩa là chỗ
này có thể nucleotide là G (guanosine) hay A (adenosine). Trong bài tập này
chúng ta không phải để ý đến những chữ này. Chúng ta để ý là trong chuỗi
GBPRI:29436 thì nó bắt đầu bằng những hàng dài nucleotides, trong khi chuỗi
GBPRI:183944 thì có những (--------) thay vào. Đó là do kết quả của sự sắp
xếp cho song song và tương đương giữa hai chuỗi. Chuỗi GBPRI:29436 thì dài
hơn chuỗi GBPRI:183944 do đó những (--------) có là do những chỗ trống thêm
vào để cho sự sắp xếp được tương đồng giữa hai chuỗi. Như chúng ta cũng thấy
là khi hai chuỗi sắp xếp song song thì tất cả những nucleotides của cả hai
chuỗi đều có mầu xanh da trời, tức là chúng giống nhau cả, ngọai trừ một
nucleotide A (adenosine) đã được thay bằng T (thymidine) ở hàng thứ tám tính
từ trên xuống dưới trong “mutant” beta-globin gene của bệnh Sickle Cell
Anemia.

Phần V:
Phiên dịch từ chuỗi Nucleic Acid (DNA) qua chuỗi Protein tương ứng.
Phần này nên dành riêng cho những sinh viên chuyên môn, đã học qua phần đầu
của môn Sinh Hoc Phân Tử, bao gồm những kiến thức về Transcription (Gene
phiên dịch), Translation (Protein phiên dịch), Exons, Introns….
Sự biến đổi gene (mutation) do sự thay đổi của một hay nhiều nucleotides
trên gene bình thường sẽ đem đến sự biến đổi của chuỗi protein do nó chỉ dẫn
để tạo ra. Để tìm ra được aminoacid nào trong chuỗi beta-globin (protein) bị
ành hưởng trong bệnh Sickle Cell Anemia, chúng ta cần biết thành phần
aminoacid của beta-globin bình thường và của người bệnh. Có hai cách để làm
điều đó khi dùng phần mềm Workbench. Trong cách đầu tiên là tìm kiếm thành
phần aminoacid của chuỗi beta-globin bình thường và của người bệnh qua sự sử
dụng “Protein Tools” thay vì sử dụng “Nucleic Tools” như chúng ta đã làm ở
phần trên. Cách thứ hai là chúng ta phiên dịch từ chuổi DNA (nucleic acid)
qua chuỗi aminoacid bằng cách dùng dụng cụ gọi là “SIXFRAME”. Dụng cụ này
phiên dịch một chuỗi nucleic acid thành SÁU chuỗi aminchuo64is gọi là
“Reading Frames”
Tại sao lại SÁU (khung đọc) “Reading Frames” khác nhau?
Điều đáng nhớ đầu tiên là chuỗi DNA là một chuỗi kép, và bất cứ một biến đồi
gene nào trong chuỗi đó thì có thể xảy ra tại một trong hai chuỗi đó, vậy là
chuỗi nào? thường ra thì chúng ta không biết được chuổi nào, do đó cả hai
đều có thể dự phần diễn dịch sang aminoacids của chuỗi protein. Do đó có sự
giải thích là có 2 trong 6 “khung đọc” phải thực hiện. Thế còn 4 khung dọc
khác là gì? Điều đáng nhớ thứ hai là cứ bộ 3 nucleotides (bases) trong mRNA
thì được dùng để “đọc” sang một aminoacid, cũng tương với 3 bases trên chuỗi
DNA. Thế nhưng đâu là nucleotide để bắt đầu cho sự diễn dịch đó? Một lần
nữa, chúng ta cũng không biết đâu sẽ là điểm khởi đầu trên mRNA, do đó chúng
ta phải đọc trên cả chuỗi mRNA. Hơn nữa, sự diễn dịch trên mRNA sẽ là từng
bộ ba “bases” đơn vị một và vị trí base ban đầu sự diễn dịch đó trên mRNA
lại không được biết, do đó toàn bộ mRNA phải được diễn dịch bắt đầu từ ba vị
trí đọc “reading frames” khác nhau trên mRNA.
Lấy ví dụ của chuỗi mRNA sau đây, sẽ có ba vị trí đọc khung (reading frames)
khác nhau tùy theo điểm đọc ban đầu bắt đầu từ base đầu A, base thứ hai A,
hay base đầu U.

Mỗi chuỗi kép DNA có hai chuỗi đơn, mỗi chuỗi chuỗi đơn sẽ được diễn dịch ra
một chuỗi đơn mRNA, mà mỗi chuỗi đơn mRNA sẽ có 3 khung đọc “reading
frames”, chính vậy với mỗi chuỗi kép DNA chúng ta có tổng cộng tới sáu khung
đọc khác nhau. Tuy nhiên trong bài tập ở đây thì chùng ta đã biết chuỗi mRNA
của cả gene bình thường và “mutant”, do đó chúng ta chỉ cần 3 khung đọc cho
mỗi chuỗi mRNA.
Phiên dịch chuỗi Beta-Globin mRNA bình thường.
Chúng ta dùng chuột chọn chuỗi beta-globin bình thường (GBPRI:29436) rồi kéo
xuống hàng “SIXFRAME-Generate & Import 6 Frames Translation on a NS”, nhấn
chuột vào hàng này rồi bấm vào nút “Run”

Trong trang kế tiếp chúng ta sẽ thấy hộp “Translation Parameters” mà chúng
ta có thể lựa chọn khung đọc nào mà chúng ta muốn chế tạo. Trong hộp “Frame
to Translate” chúng ta chọn bấm chuột vào hàng chữ “3 Forward Frames”, sau
đó vào hàng chữ “show sequench (or fragment) being translated”.
Với sự chọn lựa này, phần mềm Workbench sẽ phiên chép chuỗi mRNA thành 3 tập
thể khung đọc khác nhau. Bấm chuột vào nút “Submit”. Sau đó quyết định là ở
bạn để chọn khung đọc nào là khung đọc đúng.
Cách tìm khung đọc đúng.
Chúng ta đã có trang với 3 khung đọc khác nhau (đánh số từ 1 đến 3). Tương
đối khá dễ để tìm ra khung đọc nào là khung đúng. Bước đầu tiên là phải tìm
ra có bao nhiêu điểm dừng (stop codons) trong mỗi khung. Những điểm dừng này
được đánh dấu bằng ngôi sao (*) ở bên cạnh của base đó. Khung đọc đúng sẽ là
khung có chứa một chuỗi dài aminoacid mà không có điểm dừng. Hãy nhìn đến
từng chuỗi sau đây:


Như bạn đã thấy khung đọc số 1 có tới 7 điểm dừng rải rác dọc theo chuỗi. Do
đó, chuỗi này không thể là khung đọc đúng được. Khung đọc số 2 có tới hai
lần nhiều hơn (14) số điểm dừng, như vậy nó cũng không thể là khung đọc đúng
được. Như vậy, chỉ có khung đọc thứ ba là khung đọc dúng thôi. Chúng ta hãy
bãi bỏ hai khung đọc số 1 và 2 bằng cách xóa bỏ dấu √ trên hàng đầu của
khung. Sau đó dùng chuột kéo xuống hàng cuối của trang và bấm trên hang chữ
“Import Sequences”. Điều làm này sẽ nhập chuỗi aminoacid của khung số 3 vào
ngân hàng “Protein Tool” của phần mềm Workbench.
Diễn dịch chuỗi biến đổi (mutant) beta-globin mRNA.
Chúng ta hãy trở lại trang chủ Nucleic Acid có chứa chuỗi mRNA của
beta-globin biến đổi. Dùng chuột bấm vào nút “Nucleic Tools” ở phía trên
cùng của trang chủ Protein Tools. Hãy chọn chuỗi biến đổi beta-globin
(GBPRI:183944) và theo thứ tự sau đây như ta đã làm để diễn giải cho chuỗi
beta-globin bình thường.
Bấm nét đậm (highlight) cho hàng chữ “SIXFRAME – Generate & Import 6 Frame
Translation on a NS”.
Bấm chuột vào nút “Run”.
Bấm nét đậm vào hàng “3 Forward Frames” trong hộp “Translation Parameters”.
Bấm chuột vào nút “Show sequence (or fragment) being translated”
Bấm nút “Submit”.
Một lần nữa, bạn sẽ thấy 3 khung đọc khác nhau.. Diều các bạn cũng sẽ thấy
là có những nucleotides “X” xuất hiện, thêm vào những nucleotides “Y” và “N”
đã nói trước đây. Nucleotides “X” có nghĩa là đây là nucleotides không được
định rõ. Một khi bạn đã định được rõ đâu là khung đọc đúng (correct reading
frames) thì bạn bãi bỏ (deselect) các khung đọc không đúng kia đi, rồi bấm
vào nút “Import Sequences”
Sự sử dụng dụng cụ sắp xếp song song (alignment tools) để xác định vị trí
biến đổi đã gây ra bệnh thiếu máu lưỡi liềm.
1) Trở lại trang chủ Protein Tools mà bạn đã nhập hai khung đọc do diễn dịch
được từ Nucleic Tools (frames 1 và 3). Bây giờ là lúc chúng ta so sánh hai
chuỗi beta-globin bình thường và biến đổi để xác định đâu là aminoacid đã
gây ra bệnh Sickle Cell Anemia. Tuy nhiên, để làm được việc này chúng ta
phải sửa đổi đôi chút chuỗi aminoacids có được từ sự kết nạp từ dụng cụ
“SIXFRAME”. Trong trạng thái có được từ sự kết nạp này thì chuỗi diên giải
không dùng thẳng ngay được bởi vì dụng cụ dùng để sắp sếp song song không
nhận xét ra được dấu hiệu dừng (*) có trong chuỗi này, do đó (*) phải được
xóa đi.
2) Chọn chuỗi diễn dịch có được trong trang chủ Protein và nhấn chuột vào
hàng chữ “Edit Protein Sequence(s).
3) Bây giờ thì cả hai chuỗi aminoacids được hiện ra trong trang “Edit”. Tất
cà các chuỗi protein thì sẽ bắt đầu bằng aminoacid Methionine (M), vì vậy
chúng ta bắt đầu bằng tìm đến aminoacid M bắt đầu này. Làm sao ta có thể làm
được điều đó? Chúng ta biết rằng M bắt đầu là aminoacid tiếp theo bởi nhiều
aminoacids không bị cắt đứt bởi diểm dừng (*). Lấy ví dụ như trong khung 3,
sáu aminoacids sau điểm dừng thứ hai thí co một Methionine (M) theo sau là
một chuỗi dài aminoacids mà không đứt quãng.

4)Sau khi bạn đã xác định được M bắt đầu rồi, bấm chuột vào khung có M này
rồi chèn (insert) vào một vài khoảng trống (spaces) ở giữa M và aminoacid
đằng trước M này (như trong khung đọc 3 (Frame 3) thì chuỗi ICF*HNCVH*QPQTDT
đứng đằng trước M bắt đầu). Bấm chuột để đánh đậm nét hàng chuỗi aminoacids
(peptide) này rồi dùng delete key trong bàn máy vi tính để xóa bỏ hàng
aminoacids này.

5) Bước kế tiếp là xác định đâu là chuỗi cuối của protein diễn dịch . Điều
này sẽ được xác định bởi điểm dừng thứ nhất sau M bắt đầu, đó là điểm dừng
nằm trên hàng thứ ba của chuỗi aminoacid trong khung. Cũng như vậy, chúng ta
tách rời chuỗi này (tất cả aminoacids đằng trước điểm dừng) ra khỏi nhóm
bằng cách xóa bỏ phần đuôi (như đã làm với phần đầu) như hình chỉ dẫn sau
đây.

Sau đây là tóm tắt của vài bước sau này: những chuỗi aminoacids có mầu xanh
là những đoạn phải cắt bỏ, chuỗi đỏ còn lại sẽ là chuỗi protein diễn giải ra
từ mRNA của beta-globin có gene biến đổi.
Bây giờ ta làm sửa đổi sau đây cho khung số 1 (như đã làm cho khung 3 ở phía
trên):

Xác định vị trí cho M (methionine) bắt đầu bằng cách chọn M theo sau là
chuỗi aminoacids không bị gián đoạn bởi những điểm ngừng (stop codons *).
Xóa bỏ những đoạn aminoacids đứng trước M bắt đầu đó (nếu có). Chọn điểm
cuối của chuỗi protein bằng cách tìm đến điểm dừng (*) đầu tiên của chuỗi
sau M bắt đầu này. Xóa bỏ đoạn aminoacids sau điểm dừng (*) này.
Sau đây là kết quả của công việc làm trên. Phần in chữ xanh phải xóa bỏ.
>183944 Translated - Frame 1
(không có phần aminoacid trước M bắt đầu)
MVHLTPVEKSAVTAXWGKVNVDEVGGEALGRLLVVYPWTQRFFESFGDLSTPDA
VMGNPKVKAHGKKVLGAFSDGLAHLDNLKGTFATLSELHCDKLHVDPENFRLL
GNVLVCVLAHHFGKEFTPPVQAAYQKVVAGVANALAHKYH
*ARFLAVQFLLKVPLFPKSNY*TGGYYEGP*ASGFCLIKNIYFHC
Sau khi các bạn đã sửa đổi các chuỗi proteins có trong khung 1 và 3 rồi thì
các bạn bấm chuột vào nút “Save” đặt ở cuối trang. Bây giờ chúng ta hãy quay
lại trang chủ “Protein Tools” và các bạn sẽ nhìn thấy hai chuỗi protein mà
bạn dã sửa đổi từ khung 1 và 3 và nhập từ sự diễn dịch “SIXFRAME”.

6) Bây giờ chúng ta muốn so sánh hai chuỗi protein này để xem chúng khác
nhau ở những aminoacid(s) và ở vị trí nào. Dùng chuột để đánh đấu vào hai ô:
GBPRI:183944,SIXFRAME Translated, edited – Frame 1, và ô:
GBPRI:29436,SIXFRAME Translated, edited – Frame 3. Sau đó các bạn chọn
“CLUSTALW” va bấm chuột vào nút “Run”.

Dụng cụ Clustalw dùng để sắp xếp hai chuỗi trên dưới song song để tiện so
sánh chúng với nhau. Như kết qu3a cho thấy khi so sánh hai chuỗi beta-globin
bình thường và biến đổi, chúng ta thấy chúng giống nhau ngoại trừ ở hai
điểm.
Điểm khác biệt đầu tiên ở vị trí aminoacid số 7 của mỗi chuỗi: Trong chuỗi
protein beta-globin bình thường thì aminoacid la glutamic acid, trong khi
aminoacid ở chuỗi biến đổi lại là valine. Đây chính là sự biến đổi thực sự
đã gây ra bệnh thiếu máu luỡi liềm (Sickle Cell Anemia) mà rất nhiều người
Mỹ da đen mắc phải. Điểm khác biệt thứ hai là ở aminoacid số 15 của mỗi
chuỗi. Tuy nhiên, sự khác nhau này là do aminoacid (X) ở vị trí này đã không
xác định được một cách rõ ràng, vì vậy sự khác biệt này là không thực sự.

Kết luận
Với sự sử dụng các dụng cụ khác nhau trong phần mềm Workbench, chúng ta đã
học thấy rằng sự đột biến thay đổi xảy ra trong bệnh thiếu máu lưỡi liềm
chính là do sự biến đổi xảy ra ở mỗi một nucleotide (base) ở trong gene
(chuỗi DNA) của một trong hai chuỗi beta-g;obin của hemoglobin của hồng
huyết cầu của bệnh nhân. Sự thay đổi bắt đầu là do di truyền (genetics) của
chuỗi DNA. Sự thay đỗi này được diễn dịch (transcription) sang mRNA, sau đò
được diễn giải (translation) sang protein (beta-globin), với kết qủa là
aminoacid glutamic acid o trong chuỗi beta-globin bình thường đã bị thay
bằng aminoacid valine trong chuỗi beta-globin của bệnh nhân. Vậy tại sao có
sự biến đổi của mỗi một aminoacid trong một chuỗi hàng trăm aminoacids trong
hemoglobin lại có thể gây ra một bệnh hãi hùng, đau đớn như vậy? Muốn hiểu
rõ điều này thì chúng ta học sang phần tới của phần mềm Workbench, đó là
phần mềm 3-D dụng cụ mô hình mẫu (3-D modeling tools), nó giúp chúng ta nhìn
mô hình cấu tạo của nó trong không gian 3 chiều, và do đó có thể so sánh sự
khác nhau giữa hình thể trong không gian 3 chiều của hai loại protein này.
Phần VI.
Sử dụng phần mềm Protein Explorer để xem xét mẫu hình Hemoglobin Proteins
bình thường (Wild Type) và biến đổi (Mutant) trong không gian 3 chiều
(3-Dimention).
Trong phần đầu của bài tập này các bạn sẽ học cách để xác định nucleotide
(DNA base) và sau đó là aminoacid đã bị thay đổi để gây ra bệnh thiếu máu.
Các bạn sẽ học cách sử dụng phần mềm “Protein Explorer” để quan sát hình thể
của hemoglobin proteins ở trạng thái bình thường và trạng thái biến đổi
(mutant). Phần mềm này sẽ chỉ rõ sự khác nhau giữa hai phân tử hemoglobins
này trong không gian 3 chiều, trong đó bãn sẽ thấy rõ sự thay đổi aminoacid
từ glutamic sang valine đã làm cho hemoglobin co xụp lại và do đó hình dạng
của hồng huyết cầu trở thành hình lưỡi liềm.
Hai chuỗi proteins mà chúng ta khảo sát có tên sau đây:
1hab = hemoglobin bình thường (normal, wildtype) trong đó không có sự thay
đổi và không có bệnh.
2hbs = hemoglobin thay đổi (mutated) đã gây ra bệnh Sickle Cell Anemia.
Trước hết, chúng ta sẽ chú ý đến những hình thể của hai loại hemoglobins
này. Sau khi chúng ta đã nhớ đến hình thể của loại hemoglobin bình thường và
nhìn kỹ đến aminoacid sẽ bị thay đổi, rồi sau đó nhìn sang hình thể của phân
tử hemoglobin bị biến đổi, lúc đó bạn sẽ nhận ra sự khác biệt giữa hai phân
tử này.
CHÚ Ý: Rất quan trọng là các bạn phải tuân theo những lời chỉ dẫn từng bước
một và làm đúng như vậy. Phần mềm Protein Explorer có thể bị bế tắc nếu bạn
di chuyển chuột và thay đổi trang quá nhanh. Trong bài tập sẽ có nhiều báo
động để tránh việc làm này. Nếu để ý đến các điểm này thì mọi chuyện sẽ chạy
suông sẽ.
Phần A:
1. Chọn vào mạng Biology Workbench với địa chỉ:
http://www.workbench.sdsc.edu
2. Bấm chuột và kéo xuống cho đến khi nhìn thấy hàng chữ “Protein Explorer”.
Các bạn sẽ được dẫn đến trang mà các bạn cần phải đánh tên của protein mà
bạn muốn khảo sát. Trong bài tập này bạn các bạn sẽ đánh chữ “1hab” vào ô
chũ. Điền này sẽ mang cấu trúc cũa hemoglobins, cả dạng bình thường lẫn dạng
dị biến để được quan sát. Sau đó các bạn bấm vào nút “Go”.
3. Hãy kiên nhẫn! Công việc tải chuyển dữ liệu này sẽ cần thời gian vài giây
hay phút. Một khi trang mới được hiện ra, bấm chuột vào nút “Start Explorer
Session”. Chương mục mới với tựa đề “1ha” sau đây sẽ được hiện ra:
Báo động!!!
Đừng làm gì hết nếu bạn thấy dấu hiệu “Busy” mầu đỏ này xuất hiện, các bạn
phải đợi cho đến khi dấu hiệu đỏ (Busy)
biến thành
xanh
.
Khung hình sau đây sẽ xuất hiện.
Tuy nhiên chúng ta không nhấn vào nút cho
đến khi dấu hiệu Ready trong khung xanh xuất hiện.

Sau khi bạn đã nhấn vào nút “OK” sau khi đã nhìn thấy nút Ready xanh xuất
hiện, chúng ta phải làm một vài điều để cho chương trình không bị bế tắc.
4. Bấm chuột vào nút “Toggle Spinning”. Điều này sẽ làm cho phân tử dừng lại
mà không quay nữa và như vậy sẽ tránh được máy vi tính bị “đóng đông” lại.


Một khi phân tử đã dừng quay, chúng ta sẽ dấu kín những phân tử nước lại vì
chúng che khuất
những gì chúng ta muốn xem. Muốn làm như vậy chúng ta bấm vào nút “Hide/Show
Water”. Nếu các bạn tuân theo đúng như những lời chỉ dẫn thì các bạn sẽ được
một hình phân tử hemoglobin trông như sau:
Nếu hình trên không có được thì hãy quay lại đọc kỹ lời chỉ dẫn và bắt đầu
lại từ đầu.
5) Trước khi tiếp tục, chúng ta sẽ xem xét kỹ lưỡng phân tử hemoglobin này.
Hãy đặt mũi tên của chuột (cursor) vào phân tử và ấn nút tay trái của chuột.
Cho chuột chạy chung quay phân tử, điều này sẽ làm cho phân tử quay rồi quan
sát phân tử dưới mọi khía cạnh mà bạn muốn. Chúng ta sẽ dùng kỹ thuật này
sau này lần nữa để quan sát phân tử hemoglobin khi bị biến đổi (mutated) để
sinh ra bệnh thiếu máu.
6) Bây giờ chúng ta đi tìm phân tử biến đổi hemoglobin. Trong hộp ở trên đầu
trang và phía bên trái, chúng ta bấm vào nút “Explore More”.

Màn hình bên trái sẽ thay đổi. Bây giờ chúng ta sẽ làm một vài thay đổi để
dễ quan sát hơn.
7) Đầu tiên, chúng ta hãy thay đổi cách nhìn của protein. Bấm chuột vào bảng
có chữ “Display” (hình 1) và chọn bấm nét đậm vào hàng chữ “Cartoon”.
Chúng ta chọn “Cartoon” trong display menu bởi vì nó sẽ trình bầy cấu trúc
bậc hai (secondary structures như là vòng xoắn (helices) alpha hay khăn xếp
(sheets) beta. Cấu trúc bậc hai có được là do cấu trúc bậc nhất (primary
structures) của chuỗi protein thẳng cong gấp lại trong không gian 3 chiều.
8) Bây giờ chúng ta chọn lựa mầu sắc cho các phân tử. Bấm chuột trên bảng
“Color” và chọn mầu “Blue”. Cả phân tử sẽ đổi thành mầu xanh sau khi bấm
chuột.
9) Bây giờ chúng ta đến gần đích hơn. Chúng ta biết là biến đổi trong phân
tử hemoglobin gây ra bệnh thiếu máu lưỡi liềm là do sự biến đổi xảy ra ở
chuỗi B của phân tử. Chính vì vậy, chúng ta nên thay đổi mầu của chuỗi B vì
như vậy nó sẽ nổi bật khác với phần còn lại của phần tử và do đó chúng ta có
thể nhận diện sự biến đổi của phân tử một cách rõ ràng hơn. Bấm chuột vào
bảng “Select” và chọn “Chain B”.
Mọi sự sẽ không thay đổi ngay sau khi chúng ta bấm chuột để chọn lựa. Di
chuyển chuột đến bảng “Color” và chọn lựa “Green” (mầu xanh lá cây). Sau khi
bạn đã bấm nút “green” rồi thì chuỗi B của phân tử hemoglobin sẽ đổi thành
mầu xanh lá cây. Xoay phân tử bằng mũi tên của chuột để quan sát phân tử.
 
10) Nếu các bạn làm đúng theo như những chỉ dẫn trên thì bạn sẽ có một phân
tử trông như dưới đây.
Mầu xanh lá cây của Chain B là nơi của sự biến đổi xảy ra. Tuy nhiên, chúng
ta hãy nhìn sự kiện một cách gần hơn nữa. Bởi vì aminoacid bị thay đổi trong
bệnh thiếu máu lưỡi liềm đã xảy ra ở chuỗi B này, chúng ta có thể nhìn kỹ sự
thay đổi đó ở chuỗi này. Bây giờ hãy làm chuyện đó….
11) Bấm chuột vào hàng nút “Advanced Explorer” (có thể bạn phải kéo chuột
xuống để nhìn thấy hàng chữ này).
PHẢI NHỚ KỸ LÀ - ĐỪNG BẤM VÀO NÚT NÀO- KHI CHỮ MẦU ĐỎ “BUSY” XUẤT HIỆN Ở
PHÍA DƯỚI HÌNH CHUỖI PHÂN TỬ. PHẦN MỀM CÓ THỂ BỊ ‘BẾ TẮC’ NẾU BẠN VÔ TÌNH
BẤM VÀO.
12) Sau khi dấu hiệu “Busy” đã đổi sang “ready” thì chúng ta bấm chuột vào
nút “Sep3D” (nơi có bàn tay trong hình). Điều này sẽ cho phép chúng ta quan
sát từng aminoacid một trong chuỗi phân tử hemoglobin. Chúng ta sẽ dùng phần
mềm này để khám phá ra sự thay đổi aminoacid nào mà gây ra bệnh thiếu máu
lưỡi liềm.
13) Một trang mới với ba khung hình khác nhau sẽ hiện ra. Trong khung đầu
tiên và ở phía bên trái chúng ta chọn ”Spacefill” (trong khung bắt đầu bằng
“Ball & Stick”)

Bạn hãy bấm chuột vào hàng “Spacefill” để chọn tiêu chuẩn này rồi dời chuột
đến ô “CPK Colors” và chọn “Sec’y (secondary) Structure”. Không có gì xảy ra
cho phân tử này ngay!
14) Bây giờ các bạn nhìn xuống khung cuối ở góc bên trái Có rất nhiều hàng
chữ, mỗi chữ tượng trưng cho một aminoacid trong chuỗi hemoglobin. Chúng ta
muốn xem xét đến aminoacid (valine) đã gây ra sự thay đổi cấu trúc của chuỗi
protein này và sinh ra trao đổi giữa Oxygen và Carbonic bị gián đoạn.
Vói mũi tên chuột, nhấn vào chữ “E” đầu tiên của chuỗi B (dấu mũi tên trở
thành bàn tay như thấy trong hình trên) . Đây là aminoacid có tên là
“glutamic acid” trong hemoglobin bình thường nhưng được thay bằng “valine”
trong hemoglobin của bệnh thiếu máu lưỡi liềm. Aminoacid này nằm ở vị trí số
6 trong B chain của hemoglobin.
Khi bạn bấm chuột vào chữ E, nơi sự thay đổi đã xảy ra thì bạn sẽ nhìn thấy
sự thay đổi này trên phân tử. Nó xuất hiện như vệt đỏ trên màn hình. Đó là
nơi biến đổi xảy ra và gây ra bệnh thiếu máu lưỡi niềm. Các bạn hãy dùng
chuột để quay phân tử để quan sát sự thay đổi nhỏ trên toàn diện cơ cấu của
phân tử hemoglobin.
Phần B:
Bây giờ chúng ta đã nhìn thấy cơ cấu phân tử hemoglobin như thế nào và chúng
ta cũng xác định được vị trí của aminoacid mà từ đó sự thay đổi sẽ xảy ra.
Trong phần tới chúng ta sẽ mhìn thấy thực sự cái gì sẽ xảy ra trong phân tử
đổi biến (mutated) hemoglobin.
1) Đóng khung cửa sổ mà nó có tên của tất cả aminoacids bằng cách bấm chuột
trên hình trên cap bên góc trái của trang . (Nếu bạn không nhìn thấy khung
này có thể là bạn đang ở trang “protein viewer”, như vậy bạn phải đóng trang
này lại trước đã).
Một khi khung cửa này đóng lại rồi thì chúng ta mở (upload) một phân tử mới
đó là “2hbs” (phân tử hemoglobin bị biến đổi trong bệnh thiếu máu lưỡi
liềm).
2) Bấm chuột vào hàng có chữ “Different Molecule”.
3) Đánh hàng chữ “2hbs” vào ô ID như hình sau, sau đó bấm chuột vào nút
“Load”
 
Một khung hộp mới sẽ hiện ra ở ngay giữa màn hình. Hãy bấm vào chữ “OK”. Một
khung hộp mới xuất hiện. Bấm “OK” một lần nữa. Sau đó thì hình phân tử sẽ
hiện ra. Nhớ lại rằng, đừng làm một cái gì hết khi có dấu hiệu mầu đỏ “Busy”
ở cuối trang, góc bên phải của màn hình. Chúng ta phải đợi đến khi mầu xanh
“Ready” xuất hiện.
4) Như làm ở phần trên, chúng ta dừng phân tử đang quay lại và dấu kín phân
tử nước lại bằng cách bấm chuột trên các nút “Toggle Spinning” và “Hide/Show
Water”.
5) Bây giờ các bạn sẽ sửa đổi phân tử lại một ít như ta đã làm ở phía trên
cho phân tử hemoglobin bình thường. Hãy bấm vào nút “Explore More” ở phần
cuối trang.
6) Di chuyển chuột đến phần “COLOR” và chọn mầu “Blue”

7) Kéo chuột đến khung DISPLAY va chọn "Cartoon” để trình bầy. Phân tử sẽ
xuất hiện dưới dạng mầu xanh và có dạng hoạt họa cartoon.
8) Kéo chuột đến khung SELECT và chọn “Chain B”. Không có gì thay đổi
ngay…….
9) Đi trở lại về khung COLOR và chọn “Green”. Chuỗi B sẽ trở thành mầu xanh
lá cây.
Bây giờ bạn sẽ có hình cấu tạo của phân tử hiện ra. Tất cả phân tử sẽ có mầu
xanh da trời trong khi chuỗi B sẽ có mầu xanh lá cây. Bây giờ bạn có thể
nhìn thấy nơi nào có sự thay đổi xảy ra….
10) Bấm chuột vào hàng chữ “Advanced Explorer” (nhớ rằng có thể bạn sẽ phải
kéo chuột xuống hàng để nhìn thấy hàng chữ này).
11) Một khi trang mới được xuất hiện thì bấm chuột vào nút “Seq3D”. Điều này
sẽ trình bầy những aminoacids trong chuỗi 2hbs ihemoglobin.
12) Trong trang tới này các bạn sẽ chọn “Spacefill” ở trong khung ô bên
trái.
 
13) Chọn “Sec’y (secondary) Structure” ở trong khung phía bên phải.
Không có gì thay đổi ngay đâu……

14) Bây giờ hãy nhìn vào các phân tử aminoacids. Có một aminoacid duy nhất
thay đổi so với lần trước ở trên: thay vào vị trí E (glutamic acid,
aminoacid ở vị trí số 6) của chuỗi B. là “V” (valine). Bấm vào aminoacid
Valine thứ nhì trong chuỗi B này như hình sau đây.
Sự thay đổi một aminoacid duy nhất (từ Glutamic acid sang Valine) đã làm cho
hai phân tử hemoglobin co sát lại với nhau như bạn sẽ nhìn thấy trong hình
vẽ sau đây. Khi bạn bấm chuột vào chữ “V” thì sự thay đổi trên aminoacid sẽ
được thấy rõ như trên hình.
 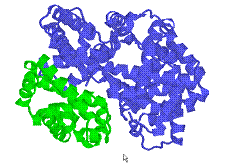
Hãy So Sánh Phân Tử Hemoglobin Biến Đổi (mutated, bên trái) và Bình Thường
(bên phải)
Thế tại làm sao cái “điểm đỏ” nhỏ bé này lại có thể gây ra sự “co dúm” của
phân tử hemoglobin lại với nhau như vậy? Vấn đề này có được lá do Valine la
một aminoacid “vô-cực, non-polar” trong khi glutamic acid là một aminoacid
“hữu-cực, polar”. Điều này có nghĩa là vì Valine không thích kết hợp, đến
gần với nước. Làm sao một phân tử “vô-cực” như là valine lại có thể tồn tại
trong môi trường trong tế bào mà ba phần tư là nước. Để “dấu mặt” những phân
tử nước này thì aminoacid này phải “co dúm” lại (ít nhất là phần bề mặt của
nó sẽ không bị phô trương ra với những phân tử nước). Trái lại, những
aminoacids “vô-cực” như Valines lại tụ hợp lại nhau tạo lại hình thể như “co
dúm” lại trong phân tử hemoglobin bị biến thể này. Khi oxygen có rất nhiều
thì phân tử này vẫn còn có thể làm được nhiệm vụ, tuy nhiên khi nồng độ
oxygen thấp như khi bắp thịt làm việc co thắt thì phân tử hemoglobin bị biến
đổi này có khuynh hướng kết tủa làm cho hồng huyết cầu biến thể thành hình
lưỡi liềm với hai mũi nhọn. Hồng huyết cầu với hình thể lưỡi liềm như vậy có
khuynh hướng bị kẹt lại ở những nơi như những mạch máu nhỏ và gây ra những
đau đớn khủng khiếp và làm bắp thịt bị thương tổn.
©
http://vietsciences.free.fr
và http://vietsciences.org
Đặng Quốc Ân
|